
What is Reddit's opinion of
Jenkins?
From 3.5 billion Reddit comments
➔ Jenkins website
By popularity on Reddit, this Service is:
100 reviews of this app found across Reddit:
Continous Integration solutions like jenkins or travis-ci are your friends.
It's technologies akin to these that allow amazon to deploy (with confidence) roughly 700 times per day.
I personally use jenkins wrapped in a docker container to deploy updates to my site after they pass a round of basic sanity tests. It's the testing and reporting frameworks that will bring joy to your life :)
Hate to ruin the joke, but Jenkins is an automated code deployment tool: https://jenkins.io/
Though this brings up the idea that people committed code and then realized they shouldn't deploy it, and were desperately Googling to figure out how to make Jenkins stop the process.
> You can run shell commands fairly easily with a sh step but only if the exit code is 0. Any other exit code will fail the build and terminate early.
Set returnCode to true, the step now doesn't fail on a non-zero exit code and returns the exit code so you can check it manually.
> You can't define a "post-build" step to execute on job failures like you can with a freestyle job.
As you are writing code this makes sense, you wrap in a try catch like you would any other language. This most certainly is not an oversight or a design quirk, we need to stop treating build scripts as some magical other domain idea and instead use common tools & patterns we use in the rest of our code.
With your implementation wrapped in a method whats the benefit of doing this instead of just wrapping the entire file in a try catch?
Also FYI you don't need to curl to slack as there is a slack plugin already.
> A serious lack of documentation.
https://jenkins.io/doc/pipeline/steps/
> No way to test your code aside from actually running it in a job.
We take vulnerabilities very seriously, so that's where I'd start. I would look through security advisories of each change log and find things that are fixed. There will be links to the related CVEs that could have a real impact if not addressed (changes here: https://jenkins.io/changelog-stable).
There's a lot more to that conversation than just security, but maybe your management responds better to that than new features? It may at least open the door for more discussion.
We use Concourse CI which defines pipelines in yaml config files and runs everything in a container, so everything can be declarative. (IIRC, Jenkins Pipeline wasn't available when tools were being evaluated.)
I had a design for a pipeline builder framework which would automatically generate pipeline config to build/test/promote/deploy anything from individual microservice Docker containers up to entire products made up of groups of services/components.
We ended up building a Python library to abstract the Concourse job/task/resource model, which made it much more concise and easier than hand-editing a yaml file. It's still config-driven in the sense that a Python script defines the pipeline, and a separate job monitors the script for changes and automatically pushes the changes to Concourse.
The challenge for scaling to the enterprise-level ended up being non-technical: groups were reluctant to switch from their existing solutions, even if they weren't far along at all.
The goal should always be magic: Tests and code get checked in, gets deployed if everything looks good, rejected if not.
How close is Jenkins Evergreen to GA?
I just finished a project upgrading Jenkins from 2.89.4 to 2.150.3, and upgraded more than 100 plugins at the same time. It was incredibly painful, and I'd love to have a "stable" set of plugins that are continuously updated.
You get some lightweight testing out of the box using declarative pipelines if the job is configured for Multibranch Pipelines: alter the Jenkinsfile and open a PR. If there's a syntax error or some other build error in the changes, it will report to your commit a failure and if you have branch protection turned on cannot be merged. Of course it will only test what was run in the `when`blocks, so if you skip a stage for pull requests then that code won't be tested.
Calm down buddy, everyone likes watching murder mystery shows, even if we don't have a chance in hell of solving the case. Personally, I think the butler a.k.a Jenkins is responsible for the dastardly deed.
Of course. Not exposed to the public. I'm believe all they had to do was follow the guidelines for credentials and secrets to obfuscate the key. You can see in the screenshot they did so with the "HOMEBREW_BINTRAY_KEY". 100% user error.
> Jenkins plugins were breaking a lot, and there wasn’t a good way to roll them back
There is a real easy way to roll your Jenkins plugins back. And it's the same as with every single other piece of software you are running. Make a backup before you upgrade.
> And because its entirely declarative, you know exactly what’s happening every time just by looking at the yaml document.
Sounds like you were using the scripted Jenkinsfiles. Those are nice because they let you do literally everything. They aren't nice because they let you do literally everything. If you care for clarity then use the declarative syntax. This is also what the documentation recommends. It will also fix your parallelization problem.
> Circle is also entirely container based, so you know exactly what your build environments are as well
I hear the Jenkins kubernetes plugin is very nice. I haven't tried it yet, though
> You dont have a huge overbearing scripting language and need to go 15 levels deep in functions to understand: everything is being called with bash.
If that's how you prefer to do things, then you can do exactly that within a Jenkinsfile. It allows you to do more. Being allowed to do things is nice, but you might not want to. You can always just shell out instead if that keeps things simple.
So yeah, sure, if you are inexperienced with hosting your own software and want to pay a ridiculous amount of money for builds as a service then use CircleCI.
Agreed that there isn't any useful info about how it is supposed to be done, and along the way, you're gonna find a plugin that you want to use, only to find out after 2 hours of configuring, that it does not support the 2.0 pipeline.
Some good documentation for me, surprisingly wasn't online, but rather the pipeline syntax snippet generator button for writing Jenkinsfiles. Those are necessary as it is what gets the plugins to work, as the rest of it is simply Groovy code.
I would say: - brush up on Groovy - use the pipeline syntax generator - understanding this: https://jenkins.io/doc/pipeline/steps/workflow-durable-task-step/#code-sh-code-shell-script - and using these variables https://jenkins.trustyou.com/env-vars.html/
This will allow you to go quite far. Feel free to PM to if you have questions as I've painstakingly written quite a lot of Jenkinsfiles.
(i wanna move away from Jenkins too, it feels like this plugin is held together by plugins, without plugins, Jenkins on its own is sorta useless)
Ideally a repo/project should be able to build on its own via the Jenkinsfile, by downloading already built version of its dependencies from a repository like artifactory or nexus.
Most projects should be multibranch pipelines nowadays, combined with build on push via hooks, this allows anyone on the team to build their changes in different branches.
If you really need to run several jobs, you can orchestrate them with the <code>build</code> step, for example, to rebuild the root project after building a new version of a dependency.
Using try/catch/finally in a declarative configuration is not a great idea since you start mixing imperative and declarative code, Jenkinsfile has post section that covers your use case keeping configuration declarative.
>folks at Jenkins recommend that you create an executor for each core on the node
This is pretty bad advice. Build is a complicated process, some steps can use more than one CPU core, even one build may require ram close to physical limit on a machine and so on and so on. You better find out how many concurrent builds are optimal for your machines and only set number of executors from this estimation.
And I didn't get why you archiving artifacts as a separate stage, this does not make sense :)
>This is why --refresh-dependencies and clean are included in this line. --refresh-dependencies is particularly important if you’re using SNAPSHOT dependencies, as I’ve run into cases where the build appears to be fine but is actually broken, and I couldn’t tell because the CI server was using a cached SNAPSHOT dependency.
Well, this is one of the reasons why snapshot dependencies are bad idea in 99% cases, you no longer have reproducible builds which kinda makes CI ~~useless~~ much less helpful.
You probably want to use a git pre-commit hook and this https://jenkins.io/doc/book/pipeline/development/#linter to do the job :) don’t make it part of the jenkins pipeline, but rather part of your overall dev workflow, with a got pre-commit hook :)
Why not? It's a good start. The key is to make your pipeline easily repeatable and reusable, then you can use your existing steps in a CI later.
​
A few important things to consider:
- Put your test code in a repository (Github or something, preferably in the same repository as the production code)
- Have Jenkins checkout and build the latest version of your tests every time the tests are run
- Since you are UI testing, make your tests configurable to run against any base URL, so that your developer can run it against multiple environments, e.g. his local, a server, production, etc.)
- Make sure your Jenkins pipeline generates an HTML test report for your dev
- Avoid installing too many random things on the Jenkins instance. This is how it becomes a mess in many companies over time. For example, if you need Chromedriver, don't just arbitrarily download it on Jenkins - add a step in your pipeline (if chromedriver file doesn't exist) { download the one I want }. This is recommended for any dependencies your test may have.
- Clean up after your job runs, if needed. In theory, your Jenkins disk and resource usage should not change after your pipeline runs, minus just an HTML report.
- Finally, and the most important piece, write a self-contained Declarative Pipeline and place the Jenkinsfile in your repository! Please avoid creating an arbitrary job on the Jenkins instance, it's generally bad practice.
Sorry if none of this is new to you, just my two cents. Once you're done all of this, you can consider the 'CI' component of this. You can look into building the codebase, and maybe deploying it somewhere before invoking your steps.
Why not just have a Python or shell script that fetches them as part of a pipeline? Assuming Python, just use datetime module to get the date and format it how you want along with standard string formatting, check with when expression to determine if log exists and run next stage, if no file run cleanup steps as needed with scripts or commands to post wherever you want. Plenty of examples with stages, steps, and error handling here.
Assuming Jenkins 2 and Jenkinsfile is how your shell steps are defined, use node labels to determine which stages and steps run on each node.
https://jenkins.io/doc/book/pipeline/syntax/
Search for Common Options
This is what I use, but I have a like/hate (love is too strong a word) with Jenkins.
At least they're trying to improve the interface (which can be really horrible) https://jenkins.io/projects/blueocean/
> Aging UI is functional but clunky - this is one of the things they're trying to improve with Jenkins 2.0
To underscore this point, it is quite telling this is an actually an improvement: https://jenkins.io/images/2.0-config-dialog.png
{kind=link}
"Dev's don't just commit and see if unit tests pass"
That's a problem that you need to solve, if devs ned to "babysit" builds, their time is being wasted, you need to aim at having an automated build environment where they commit for build, and the automated build system builds it and reports on it. I would suggest looking at jenkins as in initial step of automating builds.
Not recommended
First off... if you allow
jenkins.model.Jenkins.getInstance()
Then all it grants all users who have access to repositories to be Jenkins admins. They don’t even need access to your Jenkins instance to become an admin because of how the Jenkinsfile works.
It is the equivalent of granting everyone script console access. I recommend you reading the security warning at the top of this wiki page
https://wiki.jenkins.io/plugins/servlet/mobile?contentId=42470125#content/view/42470125
Recommended
However, you can still use it yourself as an admin by exposing advanced steps via shared pipeline libraries.
https://jenkins.io/doc/book/pipeline/shared-libraries/
It runs in the same runtime as the script console. Don’t return the Jenkins instance to users but you can use it to do more advanced pipeline things exposed as one line steps to users.
Mate, no offence, but it could be your experience with Jenkins that might be out of date.
>Its configuration(the server) cannot be defined as code which is a pain to manage plugins, credentials, etc
Everything can be scripted with groovy or, if you are lazy you can simply take the XML configuration you need from the Jenkins home (most plugin configuration is in a separate file) and put it in a certain location and that's it. Automation is very easy. Running a pre-configured Jenkins in Docker is as easy as a FROM of the official jenkins image then doing a COPY of the XML configuration you need, put your plugins and their versions in a text file and call install-plugins, then finally use groovy (ideally with docker secrets) to do all your credential setup.
>UI looks terrible
Yeah I agree it's not the greatest. Have you tried Blue Ocean ?
>There's no good way to handle multi-branch projects
Have you tried multi-branch pipelines? Works ok for me.
It might not have the best docs, fanciest UI but as far as CI servers go, i've found it to be extremely flexible and useful for both the simple and complex use cases.
> when it comes to backup procedures, DR, and maintainability I have to disagree, it's poorly design inn those areas.
These are areas where it shows its age -- bear in mind that Hudson dates back to 2005 and was only renamed to Jenkins in 2011 when Oracle tried to steal it. XML was very much in vogue at the time and a lot of the tools we take for granted didn't exist then.
I have contacts in the Jenkins community that say they're aggressively attacking these specific problems over the next 1-2 years, which will dramatically change Jenkins (one part of early work is already coming out as JenkinsX). Not clear yet if the different efforts will succeed or not, but there's a lot of people working along those lines to modernize Jenkins internals.
There's a reason companies are risk-averse with their big tools: migrations are time consuming and risky, and software with an active open source community or substantial corporate backing can change a lot over a few years.
I actually did this a couple of years ago. A big part of my job was keeping a university's lab Macs updated. Over the course of 4 months, I automated 90% of the job using a combination of Jenkins, Autopkg, and Munki. A couple of months after rolling out my solution, I was let go. In the end it worked out, though. I told my tale of woe to an interviewer and they hired me to write middleware. :)
You just need parameters for a job? We use JobDSL to create our pipeline seed jobs and point them to a Jenkinsfile for the job logic (uses pipeline 2).
For JobDSL you can create params like this:
https://jenkinsci.github.io/job-dsl-plugin/#path/pipelineJob-parameters
And then inside the Jenkinsfile / shared groovy method, you can access the parameters via params.NAME (or in quotes "${params.NAME}")
Some links: https://jenkinsci.github.io/job-dsl-plugin/#path/pipelineJob-parameters https://jenkins.io/doc/book/pipeline/syntax/#parameters
You need to get feedback as fast as possible, that's what unit tests are best for. They should run in only a matter of seconds and provide you instant feedback. Bigger integration tests can run longer.
So my setup normally looks like this: I'm using the open source Jenkins connected to my local git repository. Every time I commit, Jenkins "builds" by executing my unit tests,, smaller integration tests, and runs pylint, pep8, flake, etc.
It also has a nightly job which does the longer running integration or smoke-testing.
The testing results are automatically shown on it's dashboard, including a timeline chart of it.
Jenkins can be configured as a commit gateway, where only code is accepted into the repository, when everything yields a green result.
As of Declarative Pipeleline 1.2 you can nest stages in the Declarative pipeline -- though it all needs to be in a "pipeline" block.
But for what you want to do, probably using a scripted pipeline is better, since you can use for loops.
node('Jenkins-Slave-1') { // You need to keep the node block since you're doing parallel on the node stage('Code Checkout') { git branch: 'newFeatures', credentialsId: 'abc123', url: 'https://some-stash/scm/ip/some.git' } withCredentials([usernamePassword(credentialsId: 'abc345', usernameVariable: 'USERNAME', passwordVariable: 'PASSWORD')]){
def DeploymentType = "stage" def parallelBranches = [:] for (int i=1; i<=2; i++) { // Modify range as needed parallelBranches["Upgrade CDS Machine m${i}"] = { // Weird concatenation to avoid issues with groovy vs. env variable substitution sh 'PYTHONPATH=${pwd} python2.7 ${pwd}/prod/bounce.py -e -c -z us-west-2 ' + "-fc m${i} -go -dt ${DeploymentType} " + '-k ${USERNAME} -s ${PASSWORD}' } } } stage("Upgrade CDS"){ parallel parallelBranches } }
It's early in the morning here, so probably the above probably has some misplaced quotes or braces, but FWIW you happened to catch one of the maintainers of the pipeline plugin suite.
travis (https://travis-ci.org/) and jenkins (https://jenkins.io/) are probably the two most popular ci tools out there right now.
i don't have any experience with travis, but in jenkins you would just set up a build that monitors your repo for commits and has a command-line step that just executes your tests.
/u/IamNotTechSupport,
Just wanted to say i like your implementation of this, but you are sort of "reinventing the wheel" if im understanding this correctly.
To be clear my understanding is :
- You have a bunch of scripts that get run every day.
- They may or may not need to be run in a specific order. One after another.
- Different techs need to be able to run them.
If i'm understanding this correctly, a tool like Jenkins was built for this.
Jenkins allows you to keep all your code in your Repos (or folders if you aren't using a version control system) and create job to run tasks either at specific times or on demand. You can set it up to where it accepts input for the jobs in a form if needed. You can have it fire off a chain if you want as well. Run 1 and if it succeeds run script 2, if it fails run script 6 etc.
Again, what you've done is awesome, i'm not bagging on it. Just want to let you know there may be an easier way.
I've done this multiple times, what you are trying to do is set up a continuous deployment pipeline. You need a build server to do this. There's a few options out there:
and a few more.
The way I have it set up on several sites is via jenkins. I have a jenkins instance running on ec2 and I've set up webhooks on my github repo. When a commit is pushed to github, Jenkins fires off a job which clones the repo, does a build and pushes that change to my website (another ec2 instance, but it can be anything). If you want to gather metrics, you can do that during the build process. I grab log information from git and basically push that into a report to tell me how many commits are new from the last build, you can easily take this data and push into a webpage if you like.
I also grab the last commit, so if the build breaks (either building or unit tests) I slack the team with a link to the last commit in github as it most likely broke the build (since we build after every push)
What do you mean to work with the post section? Blue Ocean is just a more intuitive and modern view of jobs. It'll only get better (for example the editor). You should be editing your Jenkinsfile directly anyway as that gives you versioning.
Depends on what sort of integration you're looking for; in the simple case, anything that can run a command and understand an exit code is good enough. I currently use Jenkins with their declarative pipeline syntax for testing and release candidate builds, but we don't have any sort of fancy integrations with it, we use a standard shelling out to a built candidate container (essentially running sh "docker run --rm ${env.candidateImage} python manage.py test" in their Groovy DSL) which, because python manage.py test will return a non-zero exit code on failure, will just throw an error at that point and set the build as unstable (we have a bit more wrapper to do this, but this is the basic gist). A failed build test is a failed build, and we report those failures to Slack (Github if it's a PR) so it's taken care of immediately.
Long story short: a CI's job is to do a lot of things, so pick whatever fits your workflow best. I've never found a lot of benefit in extensive reporting or integrations within the CI; it's just a tool to run tasks and build releases based on actions taken in a repository (PR, merge into master, etc).
I personally stray away from most DevOps until I need it. Here's when I pick things up:
- git and GitHub: At the start. Even when I'm the only dev, it's great to be able to branch and roll things back.
- Environment management: When 1) somebody else joins, and 2) some dependencies or dev tools need to be set up. I usually use ZENv for this, but it's OSX/Linux only so it might not work for you.
- CI: When I start needing automated tasks, like pull request validation or on-commit unit tests. I'm a fan of Jenkins for this.
- Docker: When I've picked up dependencies that are hard to transfer between OSes. Sometimes though, I never hit this point and end up skipping Docker completely. It all depends on the project.
Isn't this what's done for free over at Jenkins? I wonder how these two compare in 2017. Jenkins was pretty rough getting setup back a few years ago in the Jenkins/Hudson spat with endless plugin chasing. Is TC still worth the money?
Maven is what is known as a build tool. Running javac on individual classes and bundling all those class files into a jar by hand quickly becomes unwieldy. You could write your own scripts to do all of this, but the Java ecosystem is pretty advanced and some very good build tools have been developed.
Maven in particular emphasizes convention over configuration. You write an XML file to describe your project: the name of the project, what version of the JDK you need to compile, what dependencies you have. As long as your project follows layout conventions Maven will then go through all the steps of compiling your classes, packaging them as a jar (or war or ear or whatever), and putting those build artifacts in a known location. You can extend your Maven build with plugins to do other things like generate javadocs, upload artifacts to a central repository, etc.
Bamboo is a Continuous Integration server. You might also hear about Jenkins for this role. CI is important for large projects because you don't want a change to break something in the build without somebody knowing about it quickly. CI servers can build a project and run through all its tests on every commit or on some schedule.
Jenkins Pipeline shell allows calling scripts, containing execution e.g. of python programs. By following such approach you can achieve both benefits of Jenkins and benefits of Python.
Unfortunately not. We’re running our agents in ECS which makes them ephemeral and single use so we don’t have to worry about workspaces and dirty build environments... but that doesn’t get around that the pipeline itself runs on the master :(
Here’s a decent article about scaling: https://jenkins.io/blog/2017/02/01/pipeline-scalability-best-practice/
We have multiple projects with multiple repos, however a single playbook will never be split across multiple repos in our case. This can be done, but it does add some complexity (trying to sync revisions between repos is not recommended). The one exception is that we have a separate repo for Jenkins shared libraries which we use for defining our pipeline jobs.
Some playbooks in the same repo do share roles, and we achieve this through symlinks. I don't recommend copy/pasting roles. If you want to have finer control over which playbook jobs are triggered (assuming you have multiple jobs for multiple playbooks), this can be achieved using included / excluded regions in the jenkins scm step.
We build on one set of Windows machines and test on different set of Windows machines. Both types of machines are configured as agents in the Jenkins. We have employed different types of artifact transports, including:
- Copy Artifact Plugin
- Pipeline stash
- Upload and download to and from Artifactory.
The machines being agents, Jenkins takes care of the transport and execution, and we only have to make sure the Jenkins agent is running on the nodes.
I don't think the other user understood your question.
The point of multibranch is that the Jenkinsfile gets propagated to other feature branches, and the multibranch pipeline autopopulates your pipeline with the branch name.
I'd look at the following resource: https://jenkins.io/doc/book/pipeline/jenkinsfile/
The code block /u/diabeticDayton wrote out is a scripted pipeline. I would start with declarative and stay declarative as long as possible (you can still use shared libraries inside declarative)
If your build is so complex that you absolutely need a scripted pipeline, you may want to revisit the architecture and start breaking things out into microservices.
you can find all documentation here: https://jenkins.io/doc/book/pipeline/shared-libraries/
yes, you will have repo for all scripts. these scripts will look like typical java package. you prepare some functions in shared library and use it in Jenkisnfile:
Part of Jenkinsfile: ----- checkout(#repository_with_scripts) library "ci-shared-library@$BRANCH_NAME" def buildPipeline= load("./$LIB_DIR/../buildPipeline.groovy") buildPipeline() -----
Part of buildPipeline.groovy: ----- #!groovy import com.company.ci.tools.buildSomething
def call() { ... stage('build something') {..} } -----
buildSomething - typical java package
i don't have a good example (because nda...)
Has the pluggable storage work been abandoned? https://jenkins.io/sigs/cloud-native/pluggable-storage/
The only part of it that was fully delivered was the artifacts feature.
Without the features above HA jenkins and zero downtime upgrades are very difficult and it leads a lot of people away to other CI that is more mature in this respect
Here are a few articles in case you haven't read them yet:
https://jenkins.io/doc/book/pipeline/shared-libraries/ (More tutorials on the side bar)
Great demo: https://jenkins.io/blog/2017/02/15/declarative-notifications/
I don't have any experience with a sshPut, as I use Ansible for bigger deployments. However, I do have one job where the results of a successful build are moved to a web server where they can be downloaded. I accomplished this by adding the web server as a node, and then using stash() and unstash() to easily transfer the files when complete. https://jenkins.io/doc/pipeline/steps/workflow-basic-steps/#stash-stash-some-files-to-be-used-later-in-the-build
Nope you can't directly, best you can do is run a python script from shell and give params. If this is for jenkins scripted pipeline:
def myVar = params.paramName
This can now be accessed in the script, no need for env variables.
If you have a strict requiremenr for env variables:
env.envVarName = params.paramName
Another option is that you can also wrap your job using a withEnv closure. This page has examples: https://jenkins.io/doc/pipeline/examples/
Front-end: standard HTML + ReactJS + Babel (so it works fine on somewhat older browsers)
Back-end: Ruby on Rails (cuz that's the one I am mostly familiar with... anything works though) in API mode, PostgreSQL for stuff like financial information, Cassandra for chat functions themselves (we need to deal with number of writes almost as big as reads and nobody would cry if from time to time a message couldn't go through). There are some notifications that can come from Slack to your email, I guess I would use a message broker / queue like RabbitMQ for this, same thing would be used to process uploaded files in the background. If I had to care about scaling then basically every workspace can be placed on a fully separate container/server so you can have pretty much unlimited horizontal scaling (sounds like a good use of Amazon EC2/EKS autoscaling), only few things need to go into central database (although at their scale this likely still means multiple SANs, possibly with a load balancer - let's say HAProxy - and clustered into geographical locations). Obviously we base everything on Linux, CentOS sounds reasonable. Additional stuff would be Jenkins for CI and kubernetes to provide horizontal scaling. No idea what to use for disaster recovery, I guess that for PostgreSQL itself you could use WAL files + Barman and standard SQL dumps. I am likely still missing a lot of components, coming up with a robust solution that could withstand Slack loads would require really good documentation on what exactly we are building and frankly skills vastly above mine.
Phone clients: our API already responds with JSON so this makes things easier. React Native is a simple solution since it would let you basically copy the online version. Otherwise Java for Android, Swift for iOS.
I have a situation where I have about 9 webservers that regularly need some PS interface scripts to get updated, I use https://jenkins.io/ it runs a central web server and you can install it's slave agent as a windows service on as many nodes as you want, there are plugins that will allow you to copy files to a workspace. you can set up a multi-configuration job that will run on multiple nodes, Chef might be good for this too.
This is definitely one of the problems with C++, and there are a number of different solutions but no standard one yet.
I've had a fair amount of success using cmake with the <code>ExternalProject_Add</code> function. You can point it at a git repository from somewhere like github or gitlab and it will fetch the project and add it to your build automatically. The main caveat is that it only works with other cmake projects, but cmake is quite popular.
Visual Studio 2017 has built-in support for cmake, though you can ask cmake to generate Visual Studio projects for you automatically for older versions.
I've also had a lot of success building cmake projects in Jenkins, especially using pipeline scripts written in Groovy.
rebase first, then merge -no-ff gives a prettier gitk history picture. This matters when there are more than 3 people working on the project.
typical work flow is: make a branch off the 'main' branch you will eventually commit to
- commit your changes as you set fit
- rebase periodically
- rebase and git merge -no-ff to the 'main' branch
At my work Jenkins does the final step (after compiling and running the 'basic regression' test suite). We never merge to an **official** branch ourselves.
To automate running your job you could use Jenkins
Or
Microsoft Power BI has scheduling functionality but If you would rather use VBA you could use code similar to below ( this would require leaving Excel open all the time (not a good idea). Not my code!
Not sure about the part about triggering the jobs from TFS as I don't have experience with it but for executing the same job in hundred of pipelines and managing its configuration from a central place, you should definitely look at using Jenkins shared libraries: https://jenkins.io/doc/book/pipeline/shared-libraries/
It will make your life a lot easier at the expense of a little bit of groovy code.
Still not sure I understand your usecase but a tool that might help you would be shared pipeline libraries. Then you can encapsulate and parameterize the strategy into a few methods.
https://jenkins.io/doc/book/pipeline/shared-libraries/
combined with per project jenkinsFile and a parameterized build you may be able to get what you are after.
You should move the deployment steps into shared libraries functions to be able to reuse the code and make future changes easier to propagate.
Not unless you compile PR-55 yourself. I'm surprised it hasn't been merged yet.
Another workaround would be if you could generate your coverage report as html and use an html publishing plugin, e.g.
If you're using pipeline, there's a built-in, cross-platform zip step: https://jenkins.io/doc/pipeline/steps/pipeline-utility-steps/#code-zip-code-create-zip-file
If you're not using pipeline, I believe you can use the jar executable from the JDK (if you have that installed on your nodes) to create zip files in a cross-platform manner.
So I'm a bit late here, but if you haven't checked out the new Pipeline DSL stuff, it's perfect for this:
//This lives in your project repo in a file called Jenkinsfile try { stage("Build") { //Assuming your build machines are labeled 'linux' node('linux') { //Checkout the project as specified in the git config checkout scm //do build stuff sh "put your build command here" //save files for later stash includes: '**', name: 'build' }
//Requires email plugin of course mail(to: '', subject: "${currentBuild.fullDisplayName} is ready for deployment", body: "URL: ${env.BUILD_URL}") }
//Not required, but sensible - this will automatically abort the build if you wait too long timeout(time: 1, unit: 'WEEK') { input "Approve/deny deployment to production system" }
//Optional - prevents older waiting builds from deploying if a newer build was already approved and got past this milestone label: "production"
stage("Production Deploy") { node('linux') { //restore previously saved files unstash 'build' //do deploy stuff sh("deploy shell command might go here") } } } catch(Error|Exception e) { mail(to: '', subject: "${currentBuild.fullDisplayName} failed!" body: "URL: ${env.BUILD_URL}, Error: ${e}") //Finish failing the build after telling someone about it throw e }
Surely something can be rigged up in VBA or treat Excel workbooks as SQL data source for Access. I've heard Visio can be scripted, but never attempted it myself.
Have you considered running all these scripts from a continuous integration server instead of office apps? For example Jenkins has all kinds of reporting for all the script pipelines you setup. It does not have to be used just to build and deploy software, it is at heart a framework to run and monitor script jobs. There are some visualization plug-ins and built in success/fail dependency tracking capabilities.
I did. That also led me to the Jenkins 2.0 overview page, which says that it's backwards compatible. I've been trained to not always trust the brochure. So far, though, it seems people haven't had issues with their upgrades.
Unless I missed something in the changelog?
Continuous Integration. There are lots of CI servers you can run internally that will do all sorts of things. Jenkins, for example, can build the code, run all sorts of tests (unit, integration, etc.) and even deploy that build (ideally not to production). And that's just the start.
You are asking the right questions and I like you.
Sep 30, 2021 8:38:18 AM WARNING hudson.security.csrf.CrumbFilter doFilter Found invalid crumb [64 char token]. If you are calling this URL with a script, please use the API Token instead. More information: https://jenkins.io/redirect/crumb-cannot-be-used-for-script Sep 30, 2021 8:38:18 AM WARNING hudson.security.csrf.CrumbFilter doFilter No valid crumb was included in request for /job/MyProject-%20Develop/build by LittlePrimate. Returning 403.
On the URL it says something I mistakingly disregarded at first since I misunderstood what it talks about:
"To disable this improvement you can set the system property hudson.security.csrf.DefaultCrumbIssuer.EXCLUDE_SESSION_ID to true. Alternatively, you can install the Strict Crumb Issuer Plugin which provides more options to customize the crumb validation. It allows excluding the web session ID from the validation criteria, and instead e.g. replacing it with time-based expiration for similar (or even better) protection from CSRF."
I will now try this, thank you very much.
I found links in your comment that were not hyperlinked:
I did the honors for you.
^delete ^| ^information ^| ^<3
You can have a separate agent per stage, if the stages are in sequence you can experiment if the workspace will be shared. You can however mount a dir on the slave into the container, maybe something from tmp and use that as a go between.
Check this for stage syntax https://jenkins.io/blog/2018/07/02/whats-new-declarative-piepline-13x-sequential-stages/
You can do that but it will result in a bunch of stages being created and not run.
Have you looked at this blog post? https://jenkins.io/blog/2019/11/22/welcome-to-the-matrix/
It talks about how to use excludes vs when.
It’s not running a binary. It’s running the jenkins pipeline shell step.
https://jenkins.io/doc/pipeline/steps/workflow-durable-task-step/#sh-shell-script
Put the secret in AWS Secrets Manager or AWS SSM Parameter Store, and have the job pull the secret each time it is used. https://jenkins.io/blog/2019/12/10/introducing-aws-secrets-manager-credentials-provider-plugin/
Explore solutions such as AWS SSM RunCommand that might be an alternative to Jenkins having to SSH stuff around.
You just want put the keys in the credentials manager in Jenkins. This will encrypt it at rest and allow you to use it in scripts.
​
You can then just wrap steps that require ssh with "withCredentials"
​
https://jenkins.io/blog/2019/02/06/ssh-steps-for-jenkins-pipeline/
These are pipelines defined as code (Jenkinsfile) instead of button clicky-clicky. BlueOcean project had some do docs/tutorials on it:
> you're over-complicating your setup
It's literally the first step in installing jenkins. Don't you look like a fool? What a moron
https://jenkins.io/doc/book/installing/
Do you find in life that you're quick to pass judgement but over and over you find yourself being wrong and humiliated?
If you're using a Jenkinsfile, you might be able to accomplish what you want with an "Input Step" + alert step.
https://jenkins.io/doc/pipeline/steps/pipeline-input-step/
You could send an email notification at the end of that particular stage in the pipeline with a link to the Jenkins job, and then the user can click the button to have it go forward, or abort to have it start the rollback.
Very doable. Here's a very thorough tutorial that runs you through almost that exact scenario: https://jenkins.io/doc/tutorials/build-a-multibranch-pipeline-project/
You'll still need to figure out the actual script commands or plugin calls for the deployment to azure portion but it gets you most of the way there.
You could segment all changes (content, files, etc) on staging and implement a QA checklist for file changes.
I wrote a wordpress plugin to integrate Jenkins. Basically the plugin just automates the push process.
Takes a bit of time to set up but once its running its a huge time saver.
Sure there is both with scripted pipeline and declarative pipeline.
https://jenkins.io/security/advisories/
https://groups.google.com/forum/m/?fromgroups#%21forum/jenkinsci-advisories (sorry for mobile link I'm on my phone)
The UI pulls down a JSON file from update center so you could regularly parse that if you wanted to setup.your own system.
I like echarts surprised you mentioned that seems like not a lot of people are aware. If you are willing to build the visuals yourself then that's fine. But why build from scratch?
A lot of CICD tools have visual plugins e.g. jenkins: https://jenkins.io/images/post-images/blueocean/pipeline-run.png
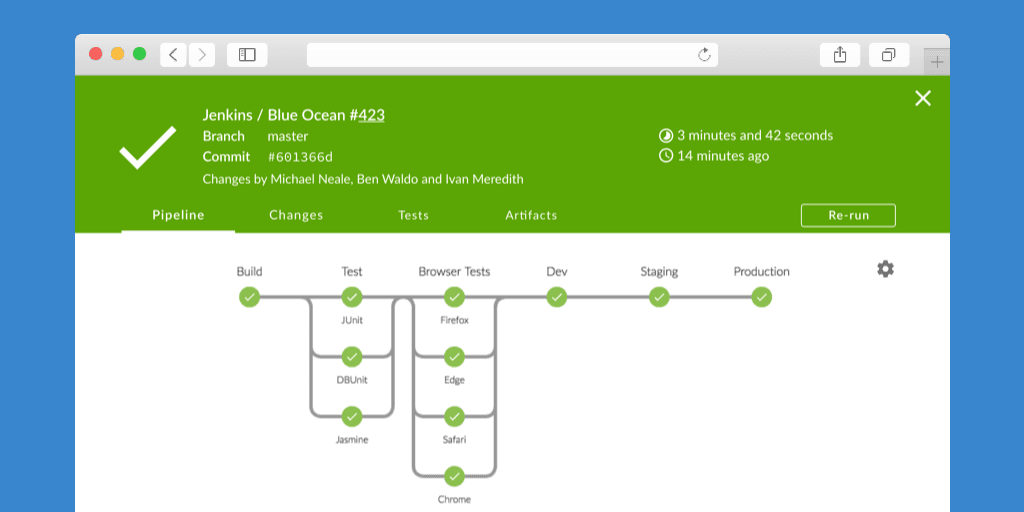{kind=link}
Unless you want someone super custom I find that a mixture of the CI dashboard and our ticket manager is usually enough to visualize releases.
I see, I don't think build parameters will help with this. Instead of defining your triggers in job B (build when job A finishes), you could let job A notify job B to start at a certain point, using the pipeline build step: https://jenkins.io/doc/pipeline/steps/pipeline-build-step/
Add this to the end of stage 3. Just adding 'build job JOB_B' should do the trick.
In this case don't forget to remove the triggers from job B though, otherwise your build will get triggered twice.
> I have a bunch of VM's that these containers could run on, but I do not care which.
This isn't something that docker addresses. This is what orchestration tools like k8s, swarm, or mesosphere concern themselves with, taking compute resources and orchestrating docker containers on to them.
All of those CI as a services that exist are orchestrating containers.
You might want Drone or maybe Jenkins. Both of these things can use non-cloud compute resources that you control to do builds.
This is a **VERY** bad idea. You're giving unfettered admin access to _all users_ who can write pipeline code. See my talk on mastering the Jenkins script console which directly applies to what you're approving here.
Or read the security warnings on the top of the wiki. As an admin I would not approve this request.
Jenkins Job Builder is probably what you want: https://docs.openstack.org/infra/jenkins-job-builder/
You create jobs in YAML, with layers of templating so you can share config and jobs across multiple projects, and when run JJB converts them to XML and loads them into Jenkins. Can keep all the job config in a git repo, so no more fiddling with the Jenkins UI.
If you're using pipeline, if you use the declarative syntax you can have your Jenkins instance lint the pipeline groovy files - see here: https://jenkins.io/doc/book/pipeline/development/#linter
If you have experience using the GUI, you'll already know the syntax for pipelines in a way. All the fields you enter in the GUI will be the same except as k,v pairs. Check out the Jenkins snippet generator and this link for shared libraries.
https://jenkins.io/doc/book/pipeline/shared-libraries/
You might not have SL's but it teaches syntax and plugin usage pretty well.
This is a good place to start.
https://jenkins.io/doc/book/pipeline/shared-libraries
That and check out the groovy documentation, their docs are actually pretty good and they have some tutorials as well.
So if you can't allow external communications into Jenkins, then you need to use polling. You can poll for changes. Or just do builds every x time.
Or you can use a middle proxy, and let GitHub let you know when there are commits and stuff.
https://jenkins.io/blog/2019/01/07/webhook-firewalls/
After that it depends on what you want to do
I ended up writing a scripted pipeline, following the guide here:
https://jenkins.io/blog/2019/12/02/matrix-building-with-scripted-pipeline/
I have to say my client didn't seem all that impressed with the user experience when compared with a "traditional" freestyle matrix job. For example, you can no longer see the build history for each specific combination of axes, or even the table of which combinations are passing and which are failing.
One of the common solutions is Jenkins.
Another new option (currently in public beta, but will soon be paid-for) is Universal Automation which is made by the same people as Universal Dashboard.
If you're looking at more general management of servers/workstations, then you may want to look at Windows Admin Center.
Are you using Jenkins Pipelines with shared libraries? The easiest thing would probably be to make the code that runs the process for Job B re-usable, and then execute that code as part of Job A.
You can definitely have a job kick off another job, wait for it, then retry, but you're likely to have a rough time trying to schedule something to run on the same node while competing with other builds. You'd probably need to wipe the agent labels, add a unique one, run the job, and then restore the labels at the end (and hope nobody force kills the job before the labels can be restored).
Shared Libraries: https://jenkins.io/doc/book/pipeline/shared-libraries/
Jenkins is an open source project and not a particular person or entity so there's not a particular person you can contact. There are many forms of community contact for general questions.
- Reddit; you found this
- Mailing lists
- Chat (internet relay chat or IRC for short)
- Issue tracker for bug reports
https://jenkins.io/participate/
See also the Community menu at the top of https://jenkins.io/participate/
Your description of the differences between scripted and declarative pipelines is flat out wrong.
Scripted pipelines support all Groovy syntax. Declarative pipelines are a simplified version.
Both can be stored either in a Jenkinsfile in your project or saved on the Jenkins server.
Both use the exact same pipeline system.
https://jenkins.io/doc/book/pipeline/syntax/#compare
If you're going to post thinly veiled advertisements for your training services, you should probably get things right.
Ah, just read the following in the docs:
> The axis and exclude directives define the static set of cells that make up the matrix. That set of combinations is generated before the start of the pipeline run. The "per-cell" directives, on the other hand, are evaluated at runtime.
I guess I need to rethink how I'm going to implement this.
You don't want to do all of that on the same node. For instance, windows, mac, and Linux aren't the same node.
I recently wrote a blog post about how to matrix build across different platforms and nodes in scripted pipeline.
https://jenkins.io/blog/2019/12/02/matrix-building-with-scripted-pipeline/
You’d think so, right? This is the assumption that I had started with too... But in reality any groovy instructions (loops, conditionals, templates, json parsing, etc) are done on the master even if you have a node or agent step... the Jenkins DSL (withMaven, sh, etc) will be done on the agent. Thanks to this you’d want to move most instruction to scripts or to use CLI like jq wherever possible.
https://jenkins.io/blog/2017/02/01/pipeline-scalability-best-practice/
If I get the time I can scrub mine of sensitive stuff and try to get an example up, but in the meantime this is a basic example that's a bit easier to understand than the official docs-
https://github.com/AndreyVMarkelov/jenkins-pipeline-shared-lib-sample
The src directory contains standard groovy classes for functions, and the vars directory contains groovy closures that Jenkins interprets as steps that can be called in your stages. In these closures. you can call the classes/functions you've defined in the src directory. Finally, your Jenkinsfile in the repo will contain your scripted or declarative pipeline.
Alternatively, you can have your entire pipeline defined in a closure in the vars directory, and the Jenkinsfile can be something as simple as:
@Library('jenkinsRepo') _ appDeploy{}
There's a few writeups and presentations on Jenkins performance tuning. I recommend watching and reading
- https://youtu.be/p0qX409wwPw
- https://youtu.be/7w2uFA5JPLI
- https://jenkins.io/blog/2016/11/21/gc-tuning/
Build out autoscaling and ephemeral agent infrastructure whenever possible.
Side note: I'm not Sam Van Oort
In Jenkins you will have in DSL called pipeline (plugin) that helps for solution this problem.
https://jenkins.io/doc/book/pipeline/syntax/#when
Using changeset to control this kind of flow. The stage will run only passed in REGEX condition.
In "pure" mkdkr there is not flow control yet but this code can filter to you.
​
pylint: ... python:3.6-buster .. pip install pylint .. 'git diff-tree --no-commit-id --name-only HEAD~1 | grep *.py | xargs -t pylint' .
The job always run, but the filter will check if the last change alter a py file
https://jenkins.io/doc/book/pipeline/docker/ <-- there's info here on how to run multiple containers.
If the only thing you need is to run your docker-compose environment so that then you ran run cypress against it, you'll need to:
- move the agent/docker portion inside the relevant steps
- ensure you have a stage that's doing docker-compose up -d before those above (and docker-compose down after, and on any error)
Docs are unclear on how to specify the network the container you want to run as stage executor, but you'll need to specify the network by name from your docker-compose environment to have connectivity from cypress to your app.
Ah, so you wouldn't have to enter any parameters in the UI again if required? That makes more sense.
Rerun is also easily confused with replay, which was a different feature in the old UI- https://jenkins.io/doc/book/pipeline/development/#replay
It doesn't look like replay is even available in blue ocean.
I’m not entirely sure I follow, maybe you can make your question clearer. What is your repo for? Which repo should cause the build to run? What type of cheddar do you have in your fridge?
The first plugin does have a poll option which takes a Boolean. May be worth starting there.
https://jenkins.io/doc/pipeline/steps/git/#-git-git
As I recall you need to have that set to false from the first time that project interacts with that repo otherwise it doesn’t pick up the new poll value, though that but may have been fixed.
There are people that can help (disclaimer I work for them). That said, while CloudBees provides commercial support for open source jenkins as well as an enterprise distribution we’re also invested in the community;
https://jenkins.io/blog/2019/11/22/jenkins-health-advisor-by-cloudbees/
I'll take a quick stab..
> How should we be handling environment variables?
It differs from ENV to ENV. We're using K8s (Kubernetes) as our container orchestrator so we handle our ENV variables in configmaps and store our secrets within K8s by using the built in secrets management tool (at least according to DevOps).
We're on OpenStack so DevOps might be performing some other magic with secrets. But that's the gist of it.
> What is generally considered best practices for CI/CD for this architecture?
We have hooks in Gerrit, as well as Github Enterprise. We're slowly migrating off of Gerrit.
Upon a merge to master the hook is triggered and a Jenkins build is kicked off. The Jenkins build file has all the information it requires to build the Docker containers, and pass those off to Kubernetes. Jenkins also runs integration tests and reports build failures which is good.
So a simple merge to master will trigger a hook in the git tool (Gerrit/Github) and the rest is automated by way of Jenkins.
TIP: for quicker container builds consider using Alpine Linux OS images.
> How should we be handling migrations?
Can you expand on that? What kind of migrations?
You would use the checkout scm step. See here.
That documentation is a little bit hard to follow. I'll see if I get an example when I'm at my computer.
You have a couple of options.
You can create a Shared Libary that is jenkins spcfic steps and scripts that can be called on other build pipelines.
If you just want to stash build scripts that are shared between projects in a git repo, you can just check it directly from your repo in your pipeline (perhaps to a subfolder) or add it as a git submodule in your projects.
You can also have different projects on different versions of your build scripts using submodules, which can be handy when updating.
For CI/CD we are currently moving from Jenkins to Azure DevOps. I set up Jenkins off my own bat because I thought it was important, and it was very straightforward. As the link shows, it's great having the test results displayed in the interface so you can identify problems quickly. There's a post-build.sh file in the repos themselves which Jenkins runs after everything's passed that handles deployment of the package and docs. Builds are started by git hooks pinging the Jenkins server whenever anything is pushed to origin/develop.
We started with DevOps after I got a new boss who was completely on board with the importance of all this stuff (that was a relief!). I really like it--I haven't got it working perfectly at the moment (in particular the rules for running build pipelines when pull requests are created, and publishing documentation as I'd like to), but the process is really slick.
One advantage of Azure is that you can define the entire build pipeline in the repo itself (I know this is the same with Travis and I believe CircleCI). It's also super easy to run the same tests on multiple Python versions.