
What is Reddit's opinion of
CodeProject?
From 3.5 billion Reddit comments
➔ CodeProject website
By popularity on Reddit, this Service is:
100 reviews of this app found across Reddit:
the code example does not have a sufficient mix of
O, o, 0, 8, |, !, I, 1, l, L, i, j, s, 5, S, Z, 2, (, {, [, ), }, ]
generally code examples showing off fonts show off these symbols close to each other often to give the viewer a good idea of how commonly used symbols might become confusing. The codeproject examples do this fairly well: http://www.codeproject.com/Articles/30040/Font-Survey-of-the-Best-Monospaced-Programming
I found the source code they were using in the background when they were describing the internet.
{kind=link}
The code in the middle is from a 2D graphics library
The code on the right is from an open source data structure implementation (shared queue).
You can write directly to VGA memory at 0xA000. This can be done under DOS, but there's nothing stopping you from making it bootable directly.
http://www.brackeen.com/vga/basics.html
http://www.codeproject.com/Articles/36907/How-to-develop-your-own-Boot-Loader
I have my pi set up with SSH certificates and no password logins allowed, see http://www.codeproject.com/Tips/600050/Raspberry-Pi-SSH-Public-Key-Authentication
Edit: I like this link better http://raspi.tv/2012/how-to-set-up-keys-and-disable-password-login-for-ssh-on-your-raspberry-pi
Nice post.
However, I'm a visual person and found this to be the most helpful description I've ever seen of visualization of inner and outer joins
{kind=link}
from here: http://www.codeproject.com/Articles/33052/Visual-Representation-of-SQL-Joins
I see a lot of criticism about this article, saying that Venn diagrams convey the meaning of joins easier, but the criticism of Venn diagrams is viable.
Let's take this picture as an example: http://www.codeproject.com/KB/database/Visual_SQL_Joins/Visual_SQL_JOINS_orig.jpg
The first join on the upper left leaves one question: Why not just say "SELECT * FROM A"? Because the LEFT JOIN actually combines both table A and table B into a result set AB (or C, if you want), while also yielding a result if there's no B corresponding to the predicate. Information that is lost in a Venn diagram and needs additional explanation!
The result will, therefore be
A1B1
A1B2
A2B3
A3NULL
But that is not what the diagram says. The Venn diagram simply states
A1
A2
A3
as long as there's no additional explanation!
The proposed diagram makes that much clearer. Yes, you have to deduct that the join predicate in the diagram is the colour, but I would argue that this is rather easy to deduce, in my opinion (matching colours = matching predicate is something that was instantly clear to me).
Instead of polling the drive every second, it's better to register for a drive removal event or just get creative with FileSystemWatcher.
To enhance the protection, consider hashing the USB serial number combined with the value from a file and use it as the myString content. This way, one can't just copy all file from your flash drive and use it to keep your computer unlocked.
I normally hate when people say this, but did even try to find an answer? This took two seconds to google:
https://github.com/dwmkerr/consolecontrol
Also:
http://stackoverflow.com/questions/355724/embedding-a-dos-console-in-a-windows-form
http://www.codeproject.com/Articles/335909/Embedding-a-Console-in-a-C-Application
Not saying they are but it's very easy to program a crawler that recognizes text or numbers in images. Hell, I've made one with limited C++ skill (not a bot but a tool to convert img2txt)
edit: http://www.codeproject.com/KB/recipes/OCRwithMODI.aspx
Go with SQLite. It fits nicely within the android environment, has a lot of support/tutorials, lots of ORMs in several fashions (simple mapping, repository pattern, active record pattern etc.) and also enough tools for editing/managing the database on your desktop.
• http://developer.android.com/training/basics/data-storage/databases.html
• http://www.codeproject.com/Articles/783073/A-Simple-Android-SQLite-Example
Some popular ORMs would be SugarORM, greenDao or OrmLite.
If there is any reason you cannot use a relational data storage or certain requirements justify the use of structured/object oriented storage, you can either use CouchDB or establish your own file system storage with e.g JSON files.
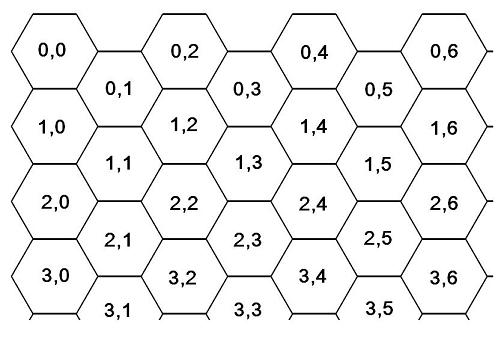
One of the advantages that both a square grid and a hexagonal gird share is that they can both be easily mapped to an x-y coordinate system. A square grid should be self-explanatory, and a hexagonal grid can be mapped as shown here. However, using the pattern in OP, this is not the case. If I had a settler at, for example, position (4, 16) what would that even mean? There is no clear answer. In order to describe a position accurately you would probably need a set of 3 or more numbers, and even one additional number could considerably increase the time for calculations, and would absolutely increase the complexity of the underlying code base.
{kind=link}
Rather than drop large patches that may be buggy it is better to do frequent smaller patches.
From a development perspective:
- things are tested by customers earlier and fed back.
- new bugs are easier to find as they are more recent to current development.
- new bugs are easier to find because there are fewer possible causes.
From a company perspective:
- Customers feedback earlier. They don't spend a whole year making a revolver that people don't want.
- Risk is reduced as smaller untested work remains. Waiting til the end to find out if things work is scary!
- They can make money sooner
They could be moving to this type of agile/continuous deployment model.
{kind=link}
The rising sales and expected long lifetime of CSGO aswell as resistance to a whole new game (because of skins etc - see 3kilksphilip) it makes sense to use this model. Typically a games company would improve the game for the next big sequel but we may not have one.
Setting up your own NuGet server would be perfect for this and allows for versioning. Bung your business logic, etc in to packages. Then you'd simply reference your packages across your solutions.
Check out this article: http://www.codeproject.com/Articles/872230/Create-Your-Own-Private-NuGet-Server-in-Windows-Az, ignore the deploying to Azure bit.
A combination of the Knapsack problem (as csticky said) and 2D packing.
Which links to an example of a rectangle packing problem: here. Though it's not trying to achieve the same thing.
In general, there's not going to be a fast algorithm for this kind of problem. This is NP-complete I believe. So while there is no general all-purpose algorithm for "weighted 2D-rectangle packing" or whatever it would be called, you could design your own based on the problem.
For example, in the case of Diablo, you could probably run through any combinations which maximise the knapsack problem, and then test for a packing. Usually in Diablo you have enough 1x1 items to make packing doable.
Alternatively, you could try a greedy algorithm: Sort by value per weight, then pack until nothing more fits. This would fail when, for example, you put a 1x4 instead of two 2x2 items which would be worth more together.
In fact, for Diablo, the maximum width of an object is 2, so this gives you another hint for optimisation.
Basically, it's not possible to construct an polynomial-time* algorithm which will guarantee you maximal/optimal usage of the inventory due to the nature of the problem. But specific algorithms can obviously be designed which will give you solutions to the problem. The performance on these depends on the problem faced.
* Thanks gman2093
People who develop libraries and API:s are pretty "good" at this. They can't decide if what they're writing is an example, a demo or a test. So it ends up being everything, which pretty much is an indecipherable mess for anyone actually looking for a simple example.
Windows programmers are the worst offenders though. Whenever they give an example for something they're hell-bent on writing a complete small demo application with a GUI. The "example" ends up being like 250-500 lines of code, of which perhaps 10-50 are even interesting for the API they're trying to explain.
Here's an example of this phenomena. According to google this is the most useful example for streaming audio in C++ using DirectX. Look at the size of that thing! Project files, multiple source files, resource files and all packed into 2 zip files. Just, wow.
My own personal rules for writing programming examples goes something like this. The example should a) do the bare minimum to achieve what it's trying to show while it b) still compiles to a complete, executable program that c) can be contained within one source file. Bonus points if it's available both on a webpage and as a downloadable source file.
Not sure about this, but I know that there are methods to inject your .exe into already running and trusted processes such as explorer.exe or svchost.exe for example.
http://www.codeproject.com/Articles/4610/Three-Ways-to-Inject-Your-Code-into-Another-Proces
This is not an analogy about a specific computer science problem, but about the life of a developer in general. I stole it from a guy's signature on Code Project years ago. I always keep a copy of it printed and post it prominently regardless of where I work.
> Imagine that you are hired to build a bridge over a river which gets slightly wider every day; sometimes it shrinks but nobody can predict when. Your client provides no concrete or steel, only timber and cut stone (but they won't tell you what kind). The coefficient of gravity changes randomly from hour to hour, as does the viscosity of air. Your only tools are a hacksaw, a chainsaw, a rubber mallet, and a length of rope.
> Welcome to my world.
> -Me explaining my job to an engineer
Constructors
So when you see something like:
= new SomeObject();
It is creating a new instance of 'SomeObject'.
You may notice that there are parenthesis '()' at the end, well it looks similar to how functions are called right?
ie Debug.Log(...) or Vector3.Distance(...,...)
This is because when you create a new instance it is executing a function within that object as soon as it is created. - This is your constructor.
So essentially it is the first function to execute when a new instance is created, and you have total control of what happens inside it.
Can be useful when setting default values or performing null checks (validation).
Structs
In c# we have two types of memory we need to consider, Value types (that go on the stack) and Reference types (that go on the heap).
A class always represents a reference type while a struct always represents a value type.
Value types are not normally referenced directly (you can by using 'ref' but lets forget about that for now). Instead of 'pointing' to the reference of the value type what happens is the value type is 'copied' into a new value.
Structs being a value type, are good for representing short containers for fields that don't have much behaviour or relationship. They take up less memory and if you use 'ref' that can be much faster to iterate over/access compared to a class.
Conclusion
Both subjects can be pretty deep for a beginner but it is important to understand so keep going until it 'twigs'.
I will leave you with a nice conversation about structs vs classes to give you more insight :)
> It's not uncommon for native script to be even 10 times faster.
I would argue with that, I'd even say that it is VERY uncommon to see that kind of difference. If your managed code runs 10x slower than the same task in C++, you might be doing something wrong. Basic calculations are not necessarily any faster with c++. C++ just offers the possibility for heavy optimization in some cases.
http://www.codeproject.com/Articles/212856/Head-to-head-benchmark-Csharp-vs-NET
Keyloggers worked how they are programmed. The most simple would be a global keyboard hook, which in layman's terms is like your program asking the operating system to be notified and allowed to handle the event every time a key is pressed. For your first example after typing "password12345" and the backspace twice the program would know every key pressed and in what order and could decide to display it however it wants, be it "password123" or "password12345<backspace><backspace>"
Your second example would fool a rudimentary keylogger like one that operates as I've just described, however, a more robust malware has many options when it comes to password stealing/interception. They can inject code into other processes, monitor network communications, alter web pages, or look on your hard disk to steal stored passwords and cookies.
Edit: Actually the most simple (stupid) key loggers I've seen use GetAsyncKeyState and actively poll every key to see if it is pressed. It seems to be a pretty bad way of doing it.
What you are looking for is this guide: http://www.codeproject.com/Articles/665518/Raspberry-Pi-as-low-cost-HD-surveillance-camera
There is a nice addition to upload them to gdrive here (see also comments): http://www.cornext.com/2014/01/make-surveillance-motion-detected.html
I was going to say to search, because there must be a ton of info out there, but then I did the search and came up without as much as I expected. So here you go:
or
http://www.codeproject.com/Articles/14948/Hexagonal-grid-for-games-and-other-projects-Part-1
or
http://www.roguebasin.com/index.php?title=Hexagonal_Tiles#Coordinate_systems_with_a_hex_grid
Good luck!
I think this kind of enthusiastic projects are critical, I feel the sleepless nights you put into figuring out the smallest details of Bitcoin and interpret them into your own system of thinking, in this case Python.
I did something similar. A tip: you might want to consider writing CodeProject articles if you want to gain greater technical interest without actual marketing.
Not sure how popular CodeProject is in Python but I was able to introduce Bitcoin to more than 10,000 developers by writing Bitcoin tutorials in C#.
after some google magic, it seems what you're looking for is a bastardized Xbox Media Center PC, aka XBMC (google that). I recommend you abandon your interest in this "UBOX" garbage and read the following sites: http://www.zdnet.com/article/the-best-hdmi-operating-system-sticks/
http://www.androidauthority.com/best-android-media-center-apps-581324/
http://www.codeproject.com/Articles/766848/How-to-build-ultimate-XBMC-HTPC-for-less-than-Kodi
That last one is the frosting on the cake. If all of this is too much to handle and you REALLY want to spend $200 on a MARKETING PLOY, by all means, keep searching, I'm sure someone will have what you request, but it won't be what you WANT. You are probably better off with a ROKU, and you can outperform that with a $30 walmart phone and a Chrome Cast.
Edit: whoops, my middle link when AWOL... fixed.
> you do have to build an entire DOM
That's not true at all. You can treat it as a text search problem. You don't have to recreate a ton of nested objects in memory. This is basically how ultra high-performance parsers like vtd-xml work.
I actually just learned about a cool method of approximating a solution to the TSP, so this might be good opportunity to share it!
It's called Ant Colony Optimization and it's based on the way that ants find the shortest path from a food source back to the mound. Check it out! http://en.wikipedia.org/wiki/Ant_colony_optimization_algorithms
And here's a paper on improved heuristics (one of the authors is the original developer of ACO): http://faculty.washington.edu/paymana/swarm/stutzle99-eaecs.pdf
And here's a project a guy did to implement the various heuristics. You can watch the ants traverse the paths and see them converge to near-optimal ones: http://www.codeproject.com/Articles/644067/Applying-Ant-Colony-Optimization-Algorithms-to-Sol#_Toc364710450
"game injecting" isn't a thing. The term is "dll injection", or more generally just "code injection". You write your code and compile it as a DLL, and then using a variety of techniques, you arrange for that library to be loaded (and by implication, its DllMain() executed) in the target process. At that point your code is running in that process and can read and write any values from the process' memory, or make API calls on behalf of the process. This is not the only way to do this — you could simply read and write the process' memory using a debugger, or programmatically through the debug APIs.
But you still would have to reverse engineer the target process to figure out where those things of interest are stored in memory. They could be at fixed offsets, or they could vary; it depends on how the game is written. (And fixed offsets can vary with each minor release/patch of the game, so they're not really fixed in any meaningful sense.) To deal with this you might:
- blindly search for some well-known byte pattern throughout each area of interest (like each thread's stack, the process' heap(s), or the .data section)
- find some fixed landmark and use that to locate the varying data
- hook a well-known API function and examine the parameters passed to it, and use their contents to get the location of the desired data
As I mentioned there are variety of techniques for injecting your DLL into another process. This article covers three of them, but there are more. You can use any language you want as long as it gives you access to the necessary APIs and the ability to produce a loadable dynamic library, although it's generally done in C or C++.
Because that's where you used to see that kind of text. I've been watching content with subs like that for a long time, before I knew about memes for certain, so I don't associate them. Also, it looks ugly because they used impact which is not an exciting font.
I'm not into anime, but this is what subs look like: http://www.codeproject.com/KB/GDI-plus/OutlineText/animescreenshot.jpg
{kind=link}
Beautiful? Not much, but at least it's very functional and readable. Fuck beauty if it impacts how well something works.
Almost never are linked lists a better choice than dynamic arrays (arrays that resize when necessary: e.g. ArrayList in Java, List in C#, list() in Python, slices in Go, std::vector in C++). Linked Lists cause the memory to be massively split up, which means every retrieval causes a cache miss. It's also O(n) to read a specific value. The only situation a linked list should be considered is in a case where arbitrary insertion / deletion is very common and arbitrary reading is not necessary. Even then, it's extremely likely that linked lists will perform much worse due to cache performance.
You have to remember, Big O does not tell you anything about how one data structure fares against another. All it tells you is the properties of the performance curve as N grows absurdly large. The performance hits LinkedLists cause in RAM operations and cache misses are much higher than any gains you get.
The primary concept for understanding why Linked Lists perform poorly is Locality of Reference.
The cost of copying an array to be able to insert a value in the middle is very cheap compared to the heavy cost of traversing a linked list.
I know I've done a lot of repeating myself here, but hopefully this sheds some light.
Here's a really great article that claims (with data) why you should never, ever use linked lists, at least for computation heavy work.
Number Crunching: Why you should never, ever, EVER use linked-list in your code again.
The DLL method, it would mean the mods can be placed outside the app and properly inside a folder, im hoping to do something like forge, but it would require 3000% more effort, forge was written using java and the code for minecraft was available this would need to call a custom dll which is the api and the dll would run the operation then convert it into assembly to call the methods inside assembly, its 100% possible but a hard process to make.
You would get the ASM/Assembly Mem-offset from the exe and inject our dll and then call the method from the dll.
It seems quite promising, but the hard part would be calling back into assembly, c++ offers a way to directly call assembly but it would be quite tricky.
Assembly inside c++ : Code Project Tut on using ASM inside C/C++ (this is what the api would use)
Side Note: I'm going to start decompiling Cube World into Callable functions tomorrow and ill stick up a github page for those curious.
Because salting.
Check this link for how a tool like you want would be created http://shiflett.org/blog/2012/jun/leakedin
Now this tool works because linkedin's passwords were hashed but not salted, which compounds the decryption process. I think reading the following link would help your understanding of the process - but in short, from my understanding, a password used on two different sites which should be employing separate/different salts will have two different resulting hashes, which would make what you're looking for infeasible.
http://www.codeproject.com/Articles/704865/Salted-Password-Hashing-Doing-it-Right
http://www.codeproject.com/Articles/274461/Very-fast-screen-capture-using-DirectX-in-Csharp
If you're going to try and cap the screen, you can't use GDI, it's too slow. DirectX should do the trick, and should even work if there's a full screen game playing.
This is type of executable obfuscation is called a packer. These techniques are common in a lot of programs, such as Spotify. Malware also uses this to evade antiviri and reverse engineers.
Overall this approach is security through obscurity and is generally considered unsustainable in the long run.
Point by point:
>* Obfuscate all variable names, function names, class names, etc...
This all depends on the language. In VM or JIT based languages you may need to do this, in machine code languages like C these don't exist on a binary level.
>* Remove all formatting and white-space.
Same as the last one.
>* Encrypt all the raw data
This is a common packer technique, but can be trivially reversed by looking at an executable running in memory.
>* Generate a hash value for each file's encrypted data
Have a look at this project
>* Generate a hash of final file name of all the installed files for project
I can't really see a reason why this would be useful
>* Store the raw file name, the file names hash value, and the encrypted data hash value in a plain raw-text-document
Again, check this out
Another useful technique is anti-debugging, it slows down reverse engineers making it very expensive to make sense of the machine code.
However, all of these things can be overcome, patched, or otherwise subverted. There is NO technique that will stop a dedicated reverse engineer from tampering with your software. If the processor can make sense of it, so can a human.
tl;dr There is no real way to stop a reverse engineer from understanding your software, but there are ways to slow them down, or make an attack too expensive.
> Apart from memory
This is the main reason. Sometimes memory (or cache) footprint is important.
The lack of a backwards pointer also makes it easier to implement things like lock-free concurrency or efficient sharing/reuse of immutable data.
That being said, singly linked lists are not good general-purpose data structures and many people will never have occasion to use them explicitly.
System.out.println will not work if you want to put text in the jframe you need to created a text area and fill it with text. Have a look at this http://www.codeproject.com/Messages/3009288/Displaying-Text-on-a-JFrame.aspx
This link should be present for any font discussion:
Font Survey: 42 of the best monospaced programming fonts
Edit: Fixed link, thanks guys.
http://sciter.com - embedded HTML/CSS UI engine. Designed by C++ programmers for C/C++ programmers (though used also in Go, Rust, Delphi and Python). Has simple plain C and C++ API (20-30 essential functions). The whole UI is made of uniform "DOM lego bricks" - defined by single API class sciter::dom::element.
"Good-looking user interface" is of course subjective. Check screenshots on frontpage for UI examples if any of them are good looking.
Essentially: Sciter provides declarative way of defining UI as a collection of markup, style, svg, png and optionally script resources that are embedded into C/C++ as resources / byte[] literals.
Script-behind-UI could be used as a "configuring glue" connecting one native function or event with others. GUI as a rule uses quite complex and unknown upfront ownership graph thus embeddeded script engine uses GC.
Sciter C++ API is quite simple: one and essential sciter::dom::element class to communicate with UI and sciter::dom::event_handler that allows to receive DOM events and expose native functions to UI.
The Sciter and technologies behind it are in production since 2006 when Norton Antivirus and other their products started using it.
I am an author of the Sciter so you can ask questions here.
Update: Sciter introductory article on CodeProject: http://www.codeproject.com/Articles/859098/Sciter-multiplatform-embeddable-HTML-CSS-scripting
Perhaps I'm biased from using it longer but IMO the Microsoft Aero glassy blur always looked superior to the OSX/iOS blur
{kind=link}
{kind=link}
Yeah they're the same, but they have a different font, same with Urdu.
Look you can notice some differences, but I (an Arab) can read all three of them.
{kind=link}
Create several demo projects that can be demonstrated on a laptop you have. If you're doing data management of any kind, you should know SQLite, mySQL and Microsoft SQL. If you work with Visual Studio, C# is the industry standard and VB.NET gets a lot of hate, but is used in some places because of it's easier approach.
Also, if you use Visual Studio, get yourself started by building a custom control. Showing that you can program far outside the System.DraggyDroppy namespace will go a far way for you. In fact, I can tell you a great place to start:
ToolStripDropDown. It's a popup container that can host any control. Used properly, you can do all sorts of awesome things. I created an autocomplete dropdown box that integrates with any existing textbox and dataset with one line of code.
Edit: Here is a codeproject article that has a very good example of the use of ToolStripDropDown: http://www.codeproject.com/Articles/17502/Simple-Popup-Control
> How we can specify both greet and hello if we want to use cargo to compile main.rs
You can't.
All names in an application exist in a single flat symbol table, and duplicates are not permitted; because it would make the execution of the application ambiguous (when calling foo(), which foo() is invoked?)
The common solution to this (that both c++ and rust use) is name mangling where a symbol is mapped to a hash (foo -> sahfkasdfhkadklsfh) which is unique for each instance; and a higher level system resolves local variables and calls to the hash before it hits the linker.
However, rust uses the c calling convention for ffi (you can read more about that here http://www.codeproject.com/Articles/1388/Calling-Conventions-Demystified), which basically means that it can only call external symbols in the standard flat c namespace.
I don't believe it's possible under any circumstances to have duplicate symbols in external libraries which are linked via ffi.
Your best bet is to manually alter the names of the symbols in the libraries to be greet_hi and hello_hi; or compile the the libraries using C++ with extern C blocks that contain unique namespaced names.
(nb. When you open a dynamic library you import the symbols into the same global namespace; but plausibly as long as you unloaded greet before invoking hello, and vice versa, you could get the behaviour you want using DynamicLibrary... but I doubt it's worth the bother)
> Moreover why is it not possible to use links without build script?
? Don't know what that means. The 'links' directive in cargo.toml basically does nothing. It just ensures no duplicates occur as a top level for crates that bind the same system library.
>The problem is I don't really know how to build it from an UX designer's perceptive.
Try replacing UXD with user perspective. No paper. No grid. No site. No code. No software solution without an extraordinarily keen understanding of some user problem. The technology will get into the project, that is not in question.
We've had too much user experience with solutions scouring the landscape in search of a problem. Of an app that hasn't found its purpose in life.
Everybody's got an excuse for an app. An excuse to use the framework they (surprise) happen to favor. An excuse to learn UXD. A way of throwing their voice to a ventriloquist dummy.
Try a user. With a problem. Instead of working inside, out, and force fitting the app, try working from the outside in.
Stop assaulting the user with excuses for you to learn stuff. Stop assaulting the customer with excuses for asking for money.
UXD tip: Never try to put lipstick on a pig. It wastes your time and annoys the pig. Lipstick on a Pig is Not UX is flat out wrong -- it is the dominant UX out there. Both online and offline. It is the user experience side of inventoritis.
You'll need to change the screen's Working Area. This looks promising: http://stackoverflow.com/questions/6267206/how-can-i-resize-the-desktop-work-area-using-the-spi-setworkarea-flag
The most elegant solution for this would be to use an AppBar though. You dock it top, bottom, left or right and Windows will know what to do. http://www.codeproject.com/KB/shell/csdoesshell3.aspx?fid=14729&select=1796941#xx1796941xx
> I'm glad they're adding translucency but... for the whole window? Just the background, like every other sane shell, please.
Sadly due to the way GDI-based rendering works, having partial transparency is a pain in the ass. Doing whole-window transparency is easy, as it's just one API call.
However, to render just the background with transparency, they would have to completely redo the client rendering to use something else that can generate an alpha channel properly. It also means they would lose automatic rendering of nonclient area, because using "true" layered windows (where you supply a PARGB bitmap) disables that, which means they would have to take that over, duplicating functionality (badly).
The problem here is twofold: first, GDI, being a 20+ year old drawing technology, has no concept of "alpha channel" at all. In fact, it sets the fourth channel to 0 for every pixel it touches in 32bpp DIBs, and there is no way to make it set it to another value. Also, COLORREFs use the the top 8 bits for palette colors. Second, as I mentioned earlier, once a window is turned into a "true" layered window, it loses its "windowness" and becomes just a sprite on screen: the system will not manage or render the non client area anymore, so no more title bars, buttons, resizing, etc.
Now of course, they have access to the underlying APIs' source code, so they could make it work, by giving the ability to supply only a client-area PARGB DIB and leave the non-client area functional. In fact, it's already possible if the DWM is on, using Direct3D, and in Win8+ the DWM is forcibly always enabled, so maybe it could work...
In my opinion, author completely misses the point of Optional type. Using it as a 'flag' for present or missing value is one of the worst use cases I can actually think of. In such case - yes, there's no real value added on top of null.
Composability is where Option/Maybe shines, you can do all kinds of projections, filtering etc. without caring if the value is really missing or not up until the last step.
So, in Scala terms, instead of following the way shown in the article:
Option[Customer] customer = getCustomer("Mark"); if(customer.isDefined) { val customerValue = customer.get
// Let's say that customer's location can also be optional if(customerValue.location.isDefined) { val locationValue = customerValue.location.get // do something with the value } }
it's way better to just do:
getCustomer("Mark").flatMap(_.location).forEach(location => /* do something with value */)
The follow up article touching on a subject of returning <code>null</code> collections also rubs me in a wrong way, mostly because the vibe I get is 'well, since there are nulls in your language/framework already, we might just as well give up on trying to improve that'. Personally, I see no reason to return null collection from any method at all...
Dropcam's a good product, no doubt about it. If, however, you want a cheaper, more DIY solution, you can get a Raspberry Pi with camera and case for around half the price of a Dropcam.
See also /r/raspberry_pi
I'll just leave this here for those who think that garbage collected languages (C# in this instance) can't leak memory: http://www.codeproject.com/Articles/21253/If-Only-We-d-Used-ANTS-Profiler-Earlier
Note that what is described in the article is not typically what is known as "DLL injection": that term generally refers to loading a DLL inside of a process that is already running -- a dynamic technique -- such as described in this article. This article employs a static technique. I'd call this article "Adding a splash screen by forcing a DLL to load by adding an IMAGE_IMPORT_DESCRIPTOR entry".
If you're keeping with Windows development, CodeProject has many decent articles and tutorials. Installing local help is invaluable, make no attempt to clutter your brain with WINAPI function parameters. Learn to work outside of and not depend on the MS development environment.
A simple tutorial http://www.codeproject.com/KB/recipes/bot_tutorial.aspx obviously they can become quite a bit more complex than this. The complexity comes from what can happen in between input and output.
**edit fixed link thanks nemec!
At some point when you're starting on AI you'll come across the concept of an FSM (Finite State Machine). Typically around the Unity community you will find examples that are made up out of Enumerators and if/else conditionals, but this is actually a very inefficient way to approach your AI States because it spirals quickly out of control and becomes horrible to maintain unless it is dealing with something VERY simple. The best way I've found to do it with coding is the State Design Pattern. This post has helped me learn about it though it's not written specific to Unity but C# as a whole. Another alternative might be to look into Assets like Behavior Designer on the Asset Store, but personally I'm not a fan of the visual programming approaches. I hope this helps you a bit :)
A couple of other alternatives are:
- Integrated security - no need to store passwords in the connection string
- Injecting the connection string as part of your build pipeline
If it were me I'd purchase a small computer such as as HP NUC, then write a small application to write the joystick values to the plc. Microsoft has code examples for reading xbox buttons and joystick values http://www.codeproject.com/Articles/16983/Using-XNA-to-Access-an-Xbox-Joystick and you could use something like advanced hmi for the drivers to the plc advancedhmi.com
Probably one of two ways--either he found a java clone or wrote one himself, or he is reading the game state from memory and altering it (it's just an array of buttons, after all).
Perhaps take a peek at using the built in XmlSerializer. Basically, create simple plain old data objects representing your question, answers, correct answer, and explanation, then put them together in a List<T>, then feed them in/out of the XmlSerializer. It will help enforce type safety and make a relatively readable/editable XML file for you.
Here's an overview/tutorial: http://www.codeproject.com/Articles/483055/XML-Serialization-and-Deserialization-Part (EDIT: Part 2 here: http://www.codeproject.com/Articles/487571/XML-Serialization-and-Deserialization-Part-2)
If you are looking to make a formless tray application, this tutorial gives you a good idea of where to start. It was a good reference for when I was picking up C# again around 2012. Some of that may be outdated/deprecated though.
You cite GoF's Design Patterns book, so just for fun I'll use the book itself to contradict your thesis.
GoF's chapters on Abstract Factories & Factory Methods don't say anything about a factory being allowed, or being forbidden from retaining created instances, so one could argue it's not essential to the pattern.
But it gets more interesting later on, where we have this curious diagram:
http://www.codeproject.com/KB/architecture/csdespat_3/flywe050.gif
{kind=link}
This diagram is from the Flyweight chapter, demonstrating a Flyweight Factory, which is instructed to retain created instances in a map and return them on repeat requests.
Q.E.D.
That aside, I do agree the contract of the method should be clear, and I do also differentiate the names of methods returning a shared instance (getFoo) from names of methods creating new instances (createFoo, or newFoo as you have it).
It does get weird with pooled instances (like in the Flyweight pattern mentioned above), as they're something in-between (neither singleton-like, neither always new). But... we have PHPDoc for that.
When you reference updating tables from other tables, can you give me a specific? Triggers are the old way of doing this, but with SQL Server 2014 (Thanks for the reminder /u/euric) there is something called 'computed columns' that should be the primary way to achieve this going forward.
As for database optimization, http://www.codeproject.com/Articles/34372/Top-steps-to-optimize-data-access-in-SQL-Server is a great guide. The number one thing you can do is learn how to utilize indexes. It's like swapping out a mechanical hard drive for a solid state drive - a simple swap that doesn't require an entire reconfiguration of the server and makes a huge immediate impact on overall performance.
I think you're confusing a linked list with a stack.
Here is just the first example on google I found of a doubly linked list implementation, just take a look at the remove function
Are you looking for a rectangle/shape packing algorithm, like that? (link on the wikipedia article on packing problems)
Since you lack on skills but not on motivation, here you go:
- Writing device drivers in Linux: A brief tutorial
- Driver Development Part 1: Introduction to Drivers
Summary:
- step 1: read and learn
- step 2: ???
- step 3: profit
On my opinion linux is doing great right now. We'll see what happens when wayland replaces x.org, but for now, we are doing great as a community.
edit: formatting
VB might be causing you issues. It (and .net in general) aren't native languages and don't generate native code. The DLLs generated aren't meant to be loaded into native programs by default, but rather other .net programs. It might not be an actual DLL basically.
You would likely need to do it in C++ unfortunately. You could take a look at http://www.codeproject.com/Articles/607352/Injecting-Net-Assemblies-Into-Unmanaged-Processes but even that seems to require using C++ to load the .net library. I would recommend just following an example for how to initialize DirectX in C++, and one on how to make a library in C++ (but make sure the latter is for Visual Studio if that's what you're using).
Good stuff!
I disagree on one point:
#Don't resort to using the .NET Framework unless absolutely necessary
From my perspective, if the .NET Framework can do it better, faster, or with fewer dependencies, IMHO you should use the .NET Framework. That being said, I would probably avoid dependencies on .NET Framework later than 3.5, unless it is unavoidable.
Example: I would never use the ActiveDirectory module in a function I write if I could instead use System.DirectoryServices.AccountManagement from .NET (Example function to pull group members without ActiveDirectory module)
It is a good analysis of the problem, but I would propose a different solution:
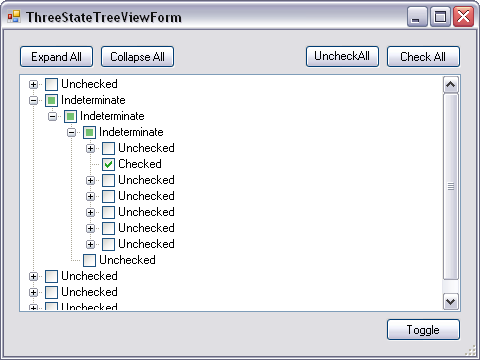
Upon registration, or as part of registration, present the users with a hierarchical selection of subreddits with checkboxes (example). The first level will consist of default subreddits, selected by default. They will be expandable to refine the choice of subreddits - e.g., /r/music will expand to /r/metal, /r/electronicmusic, etc. The advantage of this approach is that users who don't bother will not have an extra hurdle, while others will have an opportunity to customize their subreddits. This will be only used during registration; the structure of reddit will remain the same.
{kind=link}
Not all subreddits can be organized in a clean hierarchy, but this will cover many cases. Here is karmanaut's (outdated) subreddit map which is an example of how this can be done.
{kind=link}
While MrSilkyJohnsons answer by itself is great, I think you should digg a bit more into C#, OOP and programming in general. This is actually some very basic stuff in C#. Understanding the language helps fixing problems and you will know why certain things work how they work (e.g. why you can't assign the x,y,z of the position in the transform directly).
For the Monobehaviour-understanding I think you should start with this nicely written article about OOP (it looks long but it isn't actually): http://www.codeproject.com/Articles/22769/Introduction-to-Object-Oriented-Programming-Concep
Your best bet is to use some existing framework for Windows services, rather then implementing it with Win32 API. For instance: http://www.codeproject.com/Articles/781449/A-Simple-Cplusplus-Class-Framework-for-Services
I use something called ToDoList (article about it here and download/product page here )
At first glance it looks very complex, but it doesn't take long to put it to powerful use. I have my tasks setup in a hierarchy of days, where each day is a "folder" with sub tasks. Then I have a pending item group/folder at the top of the list where I pull out items I know I need to do, and I drop them into the task list for the current day.
I've been using it for nearly ten years now, and it greatly helps me with productivity and staying focused.
The problem is you are joining servers where someone has already solved the puzzle for themselves you need to find a server that has just reset the round or rent a server so you have admin powers to rest the round yourself.
Here are some resources to solve the puzzle
After you solve it and get the morse code I would record it for ~8 minutes so you have the video to work with in case your translator messes up.
I used this and a webcam to translate the morse code. It wont actually translate numbers correctly so you will need to take the actual dot and dash output and paste it into a translator you can find through google.
Think about what makes your prefabs unique. What's the difference between two enemies in your game? Is it their model? Their hp, mana, or stats in general? Do they have different attacks? All of the above?
Good news: you should only need 1 prefab, even if all of the above is different. What you need to do is use classes and inheritance to create your variety of enemies. Start by creating a new script, in which you will declare a base class for all your enemies.
In that class, you should define what is common between all enemies. Do all enemies have hp? Then define a hp variable. Can all of them attack? Then define an attack function. Then if you have enemies that are special (for example spellcasters that have mana and can throw a fireball), you will create a new class that inherits from your base class, and add the new attributes that are special to this specific enemy type, in this example a mana variable and a CastFireball function.
Then, when you want to create an enemy, you will create a new instance of the appropriate class and pass the arguments you need for this specific enemy, for example his name, his hp number, his sprite and so on.
Unity uses object oriented programming, and this right here is the basis of it. You can learn more here. Pay special attention to the "Abstraction" part, this probably exactly the answer you're looking for.
If the DLL truly exports classes (and not just functions) then I'd probably build a C++/CLI wrapper DLL. You create managed types that just shim to the native DLL. This becomes a regular managed assembly that you can import from C#.
The external angles sum to 360 because if you walk around a polygon, then every time you turn, you turn an amount equal to an external angle, and at the end, you've walked all the way around, which is 360 degrees total.
To find the sum of the internal angles, you can triangulate a polygon like this. Each of those triangles has a sum of 180 degrees and there are (n - 2) of them.
{kind=link}
I actually worked on this a while ago, tested several algoriths (median cut octrees etc) and the best looking algorithm (subjective judgement) I found was neuquant. There's a really nice implementation of it here http://sourceforge.net/projects/pngnqs9/. It's probably your best choice too because you can supply your own specific palette (the dyes) to fit the image to.
You can visually compare different algorithms using this handy tool http://www.codeproject.com/Articles/66341/A-Simple-Yet-Quite-Powerful-Palette-Quantizer-in-C
PM me if you need any help with it.
You would probably want to write a service.
I would recommend using java. Java Service Wrapper is a convenient framework you can use to simplify the process.
You could also use C++. Visual Studio has good support for creating services. Here's the top hit on Google.
I would highly recommend taking a look at the MVVM pattern.
It is a pattern that is meant to address the separation of concerns at the UI level.
You may also want to look at the Repository Pattern coupled with the Unit of Work Pattern for decoupling your data store from your business logic.
These are just a couple of patterns that I have found very useful for separating the concerns of my application in a way that is intuitive and easy to use.
For examples:
For testing your skills in developing algorithms, with and without examples (of various languages):
you can start with SSRS which is Sql Server Reporting Services this comes as a standard with MS SQL and gives you an option to install when you are installing MS SQL, if its 2005 or later. You can also connect Access to SSRS.
Refer to this link its a good starting guide http://www.codeproject.com/Articles/10377/Integrating-Microsoft-Access-DB-SQL-Reporting-Serv
If you're on Windows (Vista or later), there's the Windows Filtering Platform
Poe's Law, I guess. Unfortunately you can find articles like this which are almost definitely not satire:
The powershell tools for AD are very strong. At the very least it can create easily consumable XML for the app to do stuff with.
I mean, yeah you can probably query AD directly, but the last time I looked at that, it was a comparative spaghetti mess. e.g. http://www.codeproject.com/KB/system/getuserfrmactdircsharp.aspx
/r/learnprogramming would be a better place to ask then here.
One of these may be what you want
http://stackoverflow.com/questions/2251062/how-to-make-an-installer-for-my-c-sharp-application
http://www.codeproject.com/Articles/568476/Creating-an-MSI-Setup-Package-for-Csharp-Windows
Yeah. Was trying to make people laugh for sweet karma. I agree with you.
I, myself, am working through the Succintly series and have found them to be of high quality. http://www.codeproject.com/Articles/623589/Syncfusion-s-Succinctly-series-of-Free-ebooks
You know what's a lot more complicated than list comprehensions? Switch statements.
The reason that no one knows about this complexity is that C/C++ compilers are really good. They generate debugging information that makes it trivial to work with switch statements, even though the implementation is exceptionally complex.
I completely agree that everyone needs to be on the same page when it comes to code style. But I think the bigger problem is that Python hasn't invested nearly enough in debugging.
You need to look at Global keyboard hooks for detecting key presses, Direct Kernel Object Manipulation for hiding the process, and then you need a way to access the data. Easiest way is probably email, but it's a bad way of doing it. But really, since you had to ask you won't be able to do this without spending a ton of time so just go buy one from some "young person who thinks programming in visual basic is hacking."
YouTube - Java Tutorials for Beginners
Java Basics - Input and Output
Google is your friend - You'll want to come back when you've got some slightly more specific questions.
I wish you wouldn't be so cryptic. I guess you're referring to System.CodeDom.Compiler. Is this tutorial similar to how you built your REPL in C#?
If you're allowed to use C99 in your course, just use the C99 <code>round()</code> family of functions.
Prior to C99, ANSI C doesn't include arithmetic rounding: it has floor() and ceil() to round down and up, respectively. So you'll need to test the number you want to round to see if it's >= floor(x)+0.5 (and the opposite for rounding negative numbers). You'll also need to check first if the appropriate <type>_MAX - 0.5 > x (again, reverse the logic for <type>_MIN below zero). This may be something you'll wrap up in a utility function if you use it often.
I recommend not using <code>int</code> tricks, since they don't overflow correctly.
This helped me a ton. It breaks it down really well.
http://www.codeproject.com/Articles/1014588/A-Barebones-Implementation-of-the-MVVM-Pattern
Edit: to add to this. mvvm is really awesome, as well, if you want portable code. Like if you wanted to port your code from wpf to WinRT (universal apps) or even to mono c# as a Linux application. I try to keep these things in mind when I'm coding, to avoid as much UI code behind as possible and try to do as much UI logic in xaml as I can.
(Also makes unit testing way easier)
1) Here's one way to do it http://stackoverflow.com/a/1344242/296995
Another way is to get a random number in a range that corresponds to ascii character codes. For example if I generated a random number between 97 && 122, then convert it to a char it will be a random character between a - z.
2) Just google "enigma machine C#". Here's the first result http://www.codeproject.com/Articles/10111/Enigma-emulator-in-C
It's not going to be super basic, but it's not too hard. The enigma machine was a difficult thing to begin with.
3) You can easily capture input on a letter by letter basis. Are you doing this as a console app? desktop app? What you need will be different depending on implementation but at the end of the day you just need to call a method on every character entered.
What kind of heart rate data are you getting? ECG? Some sort of optical pulse measurement from the finger?
I am assuming ECG, so I would Google something to the effect of "realtime ECG processing C++"
You'll need to so some smoothing, some filtering, then probably do a fourier transform to pick out the frequency, then convert from frequency to Hz.
That all sounds tricky to implement in C++, so I'd suggest finding a library. <strong>Here's one example that might work.</strong>
An ORDER BY is irrelevant on an update: you're updating all records that match the criteria in your WHERE clause. A database transaction is (well, should be) an all-or-nothing thing: when your UPDATE successfully completes executing, all relevant records will be updated, and the order of their updates really just doesn't matter.
ORDERing data really only matters when you're reading it (SELECTing) out of the system.
Also, you can update multiple fields at once, rather than having to run 3 separate update statements:
UPDATE dimDate SET year = datepart(year, [dbo].[dimDate].[SupplierDate]) ,MonthName = datename(month, [dbo].[dimDate].[SupplierDate]) ,Day = datepart(day, [dbo].[dimDate].[SupplierDate])
EDIT: Give this a read, and do some more research on your own about set based vs procedural thinking. With SQL, you want to be thinking in sets - when that sort of logic clicks for you, you'll turn into a SQL wizard almost overnight :)
EDIT x2: Another link for you
Just whip up a asp.net Web api project using angularJs, and a asp.net Mvc 5-6 project using Jquery and Razor syntax and put them on your github... Shouldnt take more than a couple weeks...
Tutorials to get started... http://www.codeproject.com/Articles/992208/Angular-JS-Application-with-MVC-Web-API-ASPNET-and
I've found WPF to be the best way to make GUI's in PowerShell. It's incredible! Imagine being able to design a GUI in Visual Studio, copy the XAML, then call each of the components like
$popup.IsOpen = $true or $listview.ItemsSource = $hostcollection
So figure out how to recreate Explorer in WPF, then write the "code behind" in PowerShell. Boe Prox writes a lot of great stuff about WPF.
The advantage of WPF (and PS Studio may use it, unsure, haven't used it), is that there are a number of examples for what you're looking for.
Ok, in that aspect, procedural generation is probably going to be a serious amount of work. It can become incredibly code heavy.
I'm going to copy and paste a response from above into here regarding the resources, some of it might be quite confusing if you're still a new programmer, but hopefully it might be of some help!
> Ok so, something like this is really useful if you're wanting to have smooth transitions between different land types. Took a bit of time to get my head around, but it made such a massive different to how the game looked.
> I can post comparison screenshots of how it changed the look of my game before & after using autotiling if you'd like.
> For the creation of the world, I used this tutorial (or the first few sections at least) to handle the creation of the meshes, which in turn will handle individual 'tiles'.
> I'm at work so can't post much, but if you're wanting more info just reply and I'll see if I can be of help!
Yes, but more importantly it means MyObject.cs doesn't need to change when MyOtherObject.cs needs to change or when you add MyObject2.cs.
This might be a good read for you.
im not sure of any specific 'getting started' type tutorials, but when youve got the basics down and are ready to learn dependency properties, binding, and animation, check out this guide:
http://www.codeproject.com/Articles/140620/WPF-Tutorial-Dependency-Property
Also, find open source projects and just browse around in the source code. take note of things that are confusing or strange and dissect them one by one.
Good luck!! Learning WPF is absolutely worth your time, just push through the first couple days and things will start making sense.
You've posted a good list of resources. I loved reading articles on CodingProject when I got started - albeit not the best code, but some articles are quite entertaining.
Try StackOverflow or this sub-reddit if you get stuck, but try to overcome the hurdles yourself as that's how you learn.
It does indeed take a few hundred hours to get productive (i.e. full time months) and a couple of thousand hours of practice to specialize in solving particular problems.
You basically have to write a simulated screen/console controller. You have to handle splitting strings over lines, backspacing and deleting text, etc.
There may be a console controller script in the asset store.
Edit: Something like this I guess http://www.codeproject.com/Articles/9621/ShellControl-A-console-emulation-control
You do know you can just go to any forum and get some help... free, right?
try http://www.codeproject.com/ for example
"give a man a fish..."
Stack Overflow is my go-to when facing challenges: http://stackoverflow.com/
It's quite late in here and I'm not really willing to go into your assignment at this hour, but those seem really straightforward, you should get them solved in half an hour tops.
Also refer to https://msdn.microsoft.com/en-us/library/ms189799.aspx?f=255&MSPPError=-2147217396 for more info