
What is Reddit's opinion of
OCCT?
From 3.5 billion Reddit comments
100 reviews of this app found across Reddit:
Sounds like your PSU is dying or it's not supplying enough power under load (i.e., defective) or something is triggering possibly OCP to make it restart
I would replace the PSU anyways due to Thermaltake Smart 500W being extremely low quality group-regulated design: https://superuser.com/questions/1051024/under-what-conditions-will-a-group-regulated-psu-damage-a-modern-computer
Thermaltake lies about the actual wattage as well. Its actual wattage is only 420W reported by the 12v rail: https://www.thermaltakeusa.com/smart-500w.html
I would maybe run OCCT Power supply stress test: https://www.ocbase.com/
If the test fails, then it's most likely a PSU issue
I would only buy DC-DC topology PSUs with 5 years warranty at least, if you value your PC parts not dying.
CPU pulled 260W even (not R23, different load). It depends on load and cooling. Basically, more Watts of heat you can remove with cooling, more Watts of power CPU can pull, up to a point. With static OC ppl were pulling way too much, above 300W easy. Pulling more Watts won't make better results. It's all about balance of things. You can check OCCT bench results , just switch to 5950x in dropdown, and look at multicore AVX and SSE loads. You'll see my results in top 10 pulling the least amount of power of all there, 2nd lowest voltage (just 4mV difference) but way lower temps than others (click on white arrow to open individual results, scroll down and look at temps, power, current etc). If you'd look at scores better than mine, and compare temps, you'd see that mine are in mid 70s, while some go even above 100C. I'm not gonna run my CPU at 103C pulling ~200A and 250-300W just to move one spot up in some bench. If THAT'S what takes to beat my daily, then I'm happy, and they can keep their spots.
{kind=link}
Download OCCT (free) and try to run the full benchmark a few times. Result doesn't matter, just if you'll get any errors while running it. Alternatively you can set AVX and run just that one. It's pretty fast and good for exposing "easier" errors.
As most people have said, it is likely that the GPU is faulty, however the fact that is only showing in some games and not others could indicate your GPU is having difficulty with specific memory functions, instructions or libraries that these games utilise.
My advice would be to investigate all software or environmental variables before looking at a hardware issue as software, configuration or environmental issues aren’t covered under a manufacturers warranty.
Re-install video drivers, ensure your drivers are configured correctly (as I notice in another comment you say your laptop has both an integrated and dedicated GPU) and I’d go as far as installing Windows onto an external drive, installing required drivers and just one of the games to see if the issue follows a fresh OS.
In the environment space, ensure all fans & heat sinks are free of dust and debris. I find having the laptop on a stand or elevated allows for better airflow/cooling and if you play with an external monitor connected, have the laptop lid open to allow heat to escape and just disable the display in the Windows settings app. Being an almost 2 year old gaming laptop, there is a chance that you may need to replace the thermal paste on your GPU as most laptop OEMs don’t put the best thermal paste (and even sometimes not enough) when assembling the laptop.
For hardware diagnostics, some laptops come with a built in diagnostic tool in the BIOS but check the manual of the model to be sure. You can always use third party tools in this case as it’s for GPU artefacts, there’s a tool called OCCT (https://www.ocbase.com) you can use to run tests against your GPU and it’s VRAM but also MemTest86 to check for any RAM issues (as the GPU will piggyback off your system RAM if it’s running low on VRAM).
Hope that helps.
How hot is your GPU getting? What kind of crashes?
Are you getting any BSOD?
Just crash to desktop? DXGI errors?
Might be better off using OCCT to diagnose such issues: https://www.ocbase.com/
I would use GPU stress test from OCCT maybe first and see if it passes that.
If it does, stress test other stuff like RAM and CPU
Any giant addons can do this.. I'm not sure if there's an addon profiler but that might help to see if it's something addon related.
If I was you I'd launch resource monitor and let it collect afew good examples and then check to see if anything shows on the graphs.. From there, with system times from the graphs i'd go check the event viewer to make sure you're not getting any meaty events ( I.E a failing power supply). If you're getting perfomance related events i'd get OCCT ( https://www.ocbase.com ) and perform a stress test to see if you get any errors.
I'd also perform a clean re-install of the latest Nvidia Drivers, unless you're staying with a certain version and in that case i'd still do a clean re-install of that driver.
I used:
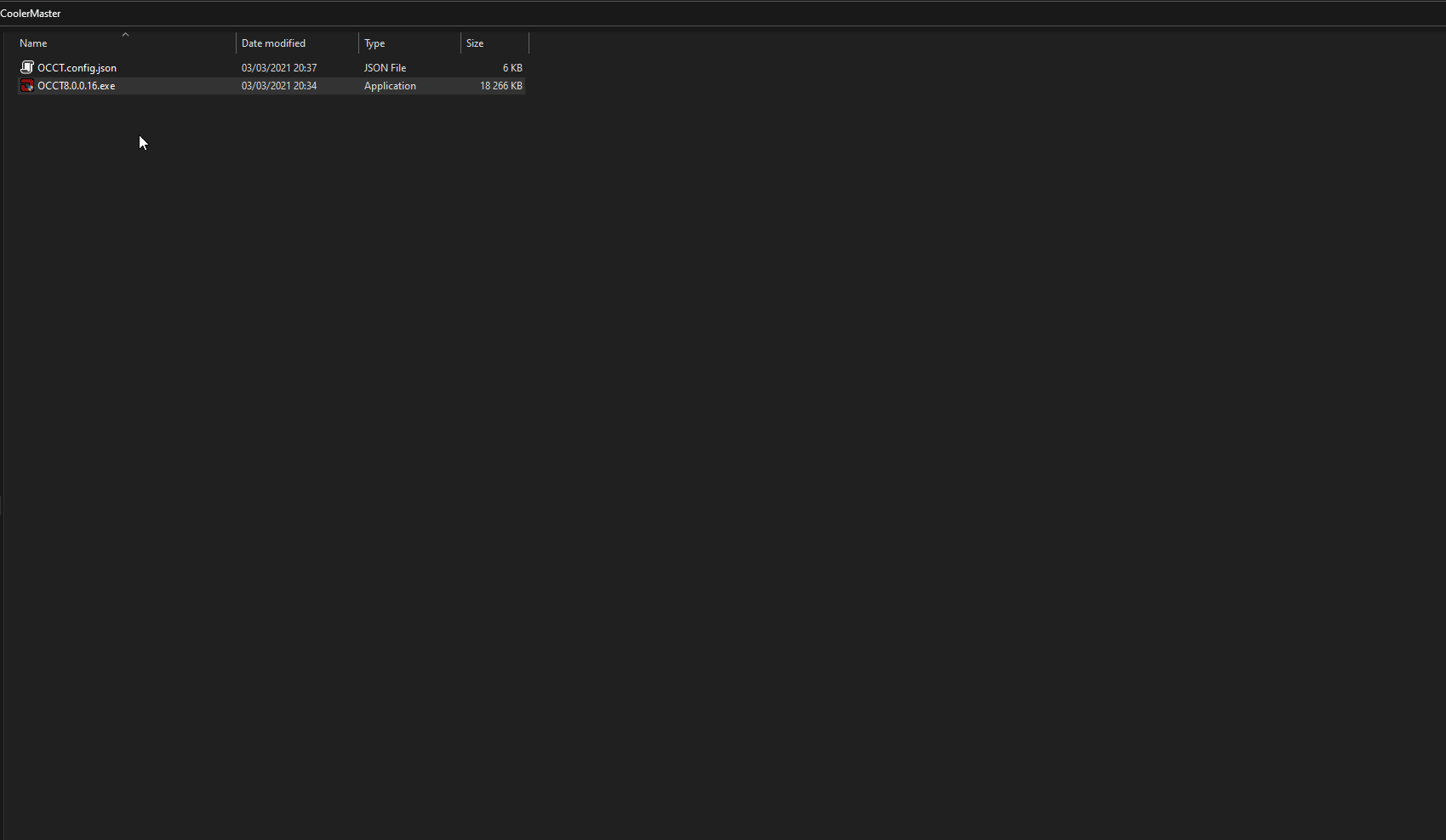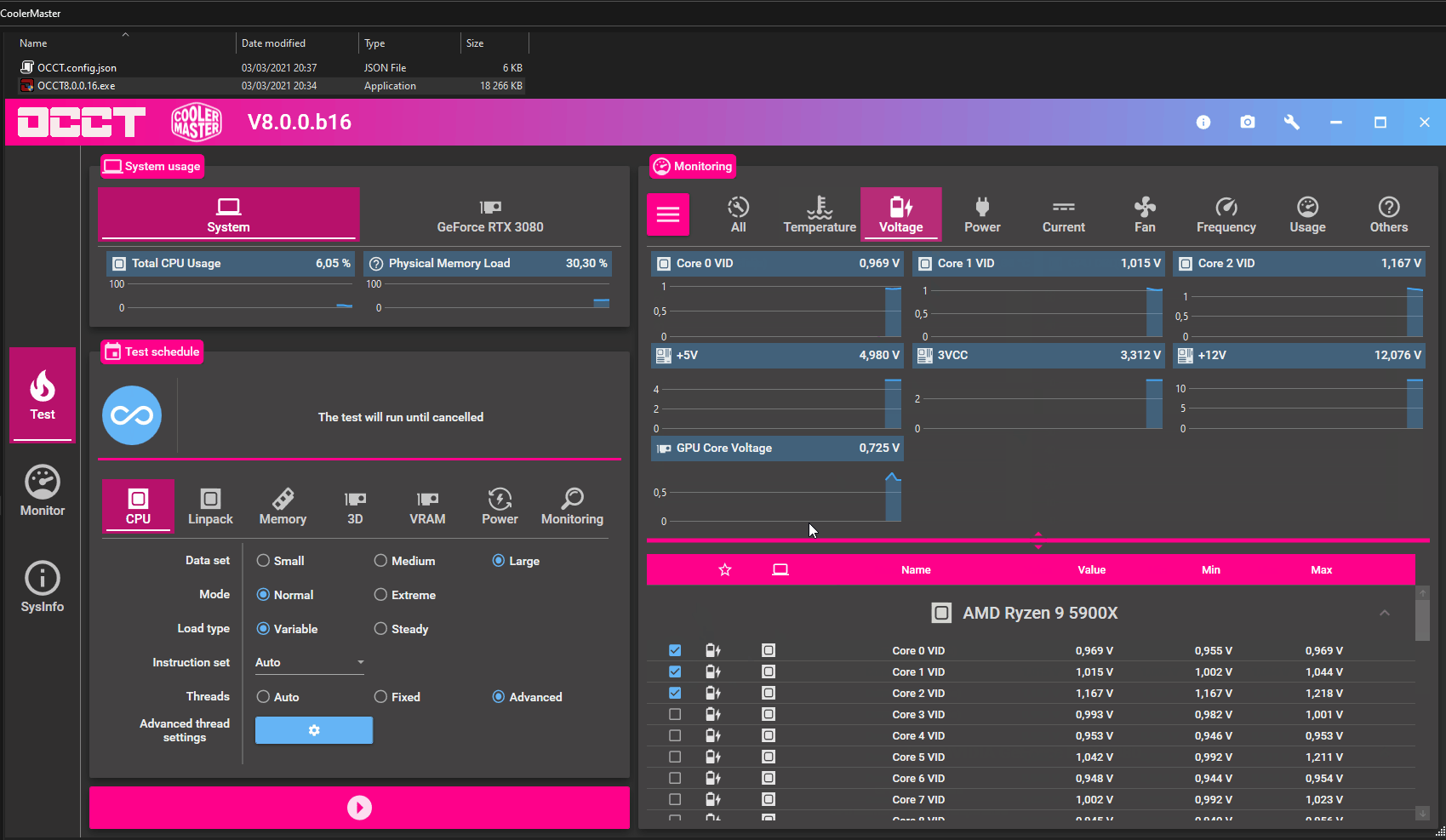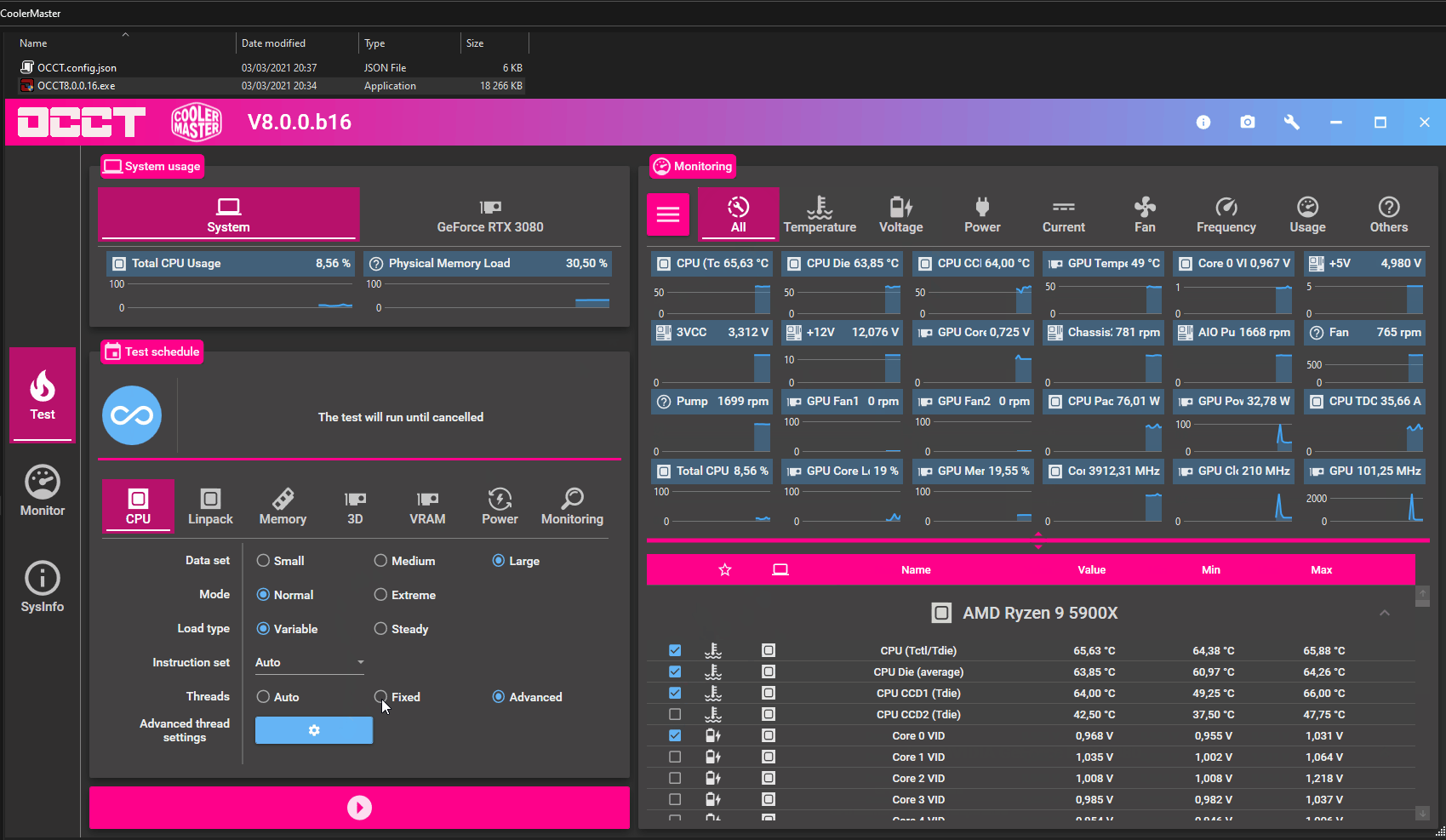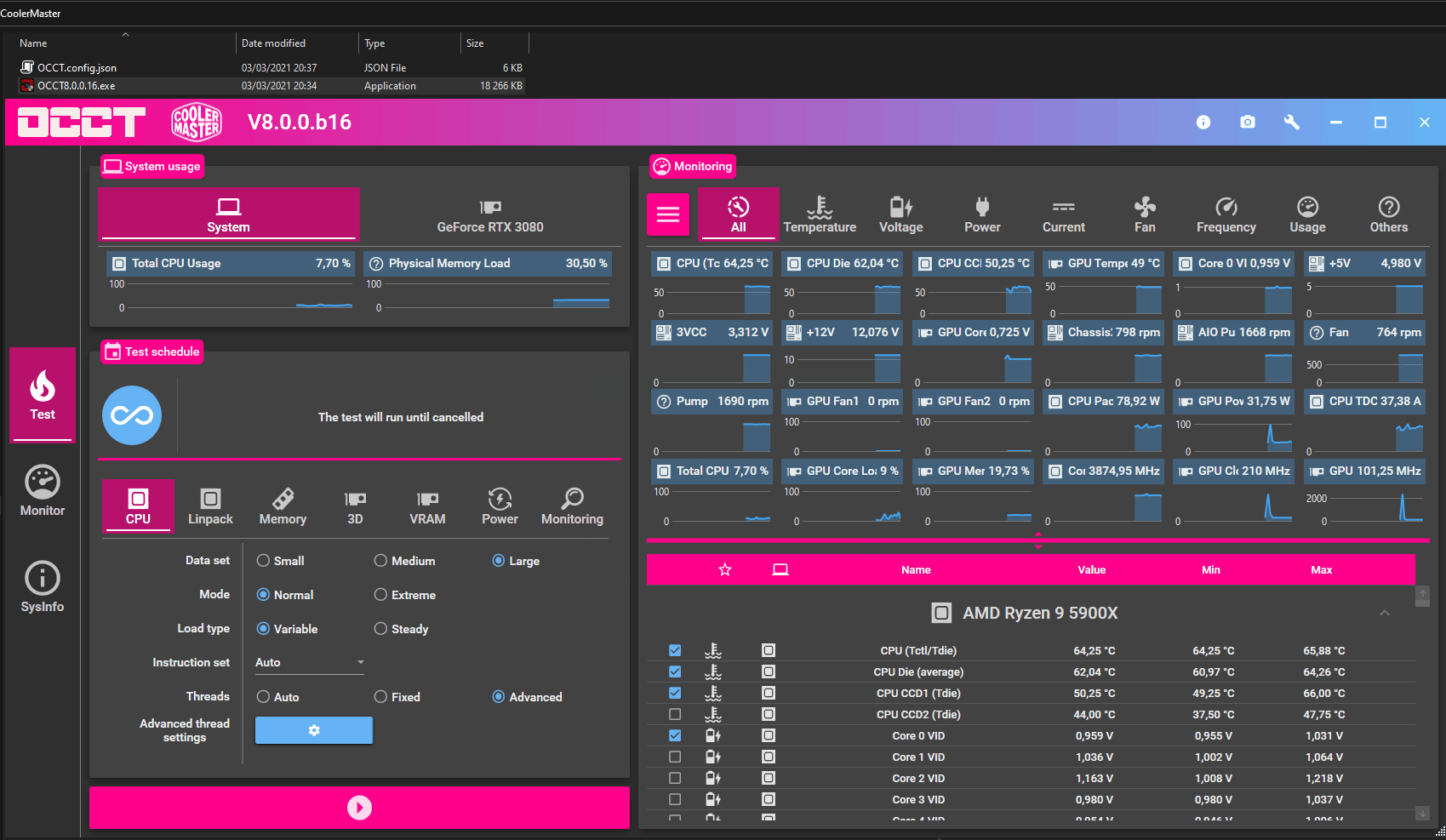
OCCT 8.x.x from https://www.ocbase.com/
- CPU test
- Data set: Large
- Mode: Extreme
- Load type: Variable
- Instructions set: Auto
- Threads: Advanced
Then click on the Advanced Thread Settings button and in that page:
- Unselect all Physical Cores but Core #0
- Virtual Cores: Physical Only,
- Core Cycle: Cycle Active Core every 5s,
- Swap Active/Inactive Cores: Disabled
Just start it after setting all cores to -15 in CO and let it go for 10 minutes. It will show a log line for each time that a specific core gave an error. After 10 minutes of that test you can collect all cores that gave errors in the logs (in my case they were cores 1 3 and 9 for example) , go in your BIOS Curve Optimizer and put cores 1 3 an 9 to -10 and all other cores to -20, then run the OCCT test again for 10 more minutes, and go on with additional negative or positive offset to each core (5 at a time, or 2 at a time later when you want to fine tune).
That's all
OCCT - https://www.ocbase.com/ was another one from what I remember, comes complete with the ability to stop itself if a component reaches a certain threshold it seems.
Something reaching a certain temperature for example.
Run OCCT GPU stress test and maybe the GPU VRAM stress test and see if it passes: https://www.ocbase.com/
Crashing during heaven which is much more GPU demanding than minecraft may indicate issues with the integrated graphics
Run OCCT memory stress test: https://www.ocbase.com/
Just use the default settings for the memory tab section. It will run for an hour. Page faults and system service exception is usually related to faulty or dying RAM
I think you need to run a gpu memory stress test.
A quick google found a couple options that people like:
May have to run them for 10+ minutes or so (whatever time your glitch seems to happen after) and see if it could just be your hardware :(
I....
I would make sure PSU is 100% fine first, IMO
That really, really sounds like PSU is dying.
OCCT has a PSU stress test: https://www.ocbase.com/
But not sure how reliable it is.
The ideal test I think is to get a different PSU and see if you still crash :(
GTA V is more demanding than you think.
If you’re sure it’s not a heat problem grab https://www.ocbase.com and do a psu test, I don’t know your laptops manufacturer but from the gpu it’s up to 6 years old now
https://www.ocbase.com/misc/cooler.master.occt.gif
{kind=link}
How about branding a popular Stability testing app like OCCT ?
This is the kind of branding I'd like to see personally ;)
How hot is your CPU running? If your system is starting to slow down when it warms up it could be overheating. I recommend using a program like OCCT to verify how hot things get under load. It has CPU and GPU stress tests.
As for crashing to the desktop, unfortunately it can have many causes, but a defective GPU is a possibility.
Reset bios, and Re-activate XMP so you can fully test the power. Then download OCCT and start the option "Power". If your pc turns off within 10 seconds, then your PSU is probably the reason it shuts down
Those sticks are DDR which is double data rate they true speed is half of what they are advertised at. If you load up CPUz or HWINFO64 those utilities will report their true speed which is half of what is advertised or the value you set in the bios.
So you would not do 15 divided by 3466 x 1000 to get your latency, you need to use 1733 the true base speed of the memory.
The official memory support for the 1800X is 2666 MHz anything over that and you doing good. When these chips first came getting 2933 MHz was a big deal. The bios updates since then really improved things.
If you are doing anything other than playing games I would stress it with something like OCCT , Prime 95, or RAM Test . Memtest is ok but it passes some timings that are unstable if you don't let it run for really long time.
OCCT is the name of the stress testing software I was recommending for testing CPU core / cache stability, you can find more info and a download link for it here on their website. If you can pass one hour of the LDS test (Large Data Set) without any errors you can assume your system is pretty stable, two hours if you want to be extra thorough.
I wouldn't be concerned at all if my CPU reached 80 C when stress testing, I start paying attention my temps when they approach 90 C.
Most motherboards automatically reset some settings like memory to default when there is a hardware crash. So that is normal.
But what causes the crash usually requires some testing. The PSU is the primary suspect when machine crashes on heavy load. You could test with something like OCCT and see what happens when you run the CPU test, then the GPU test and then the PSU test (both CPU and GPU test at the same time).
Cheap PSU's are pretty dangerous. You might want to upgrade, quality Corsair / Seasonic PSU's have very long warranties because they know they last.
You could test with PSU test, like the one in OCCT. But if your PSU is already about to fail, it might be bad for the computer.
I'm not exactly sure what would cause that issue, but here are a few things you could try:
- make sure the sticks are in the right slots (see motherboard manual)
- double-check that you've selected the right XMP profile, and use HWiNFO to verify speed/timings/voltage (should be 1600MHz/16-18-18-36/1.35V DRAM voltage)
- test each stick individually, with and without XMP enabled; if the problem only occurs with one stick, try to get a replacement through Amazon
- if your kit is fine with XMP disabled, try to manually set primary timings and voltages (16-18-18-36, 1.35V DRAM voltage, 1.10-1.15V VCCSA/VCCIO voltage), then raise the speed gradually and test for stability with each increase—I prefer OCCT for testing stability, but there are plenty of other options
Let me know if any of this helps or if anything here needs clarification.
Yes, the information is stored in a chip on the memory module and it is read by the motherboard, so it will appear in BIOS. With MSI's "easy mode" UEFI BIOS the XMP enable button should be easily noticeable on the front page.
I recommend running 1 hour of OCCT: https://www.ocbase.com/. "Memory" > "SSE" and go with default settings for an hour. If it passes it's good.
> bsod error code: CLOCK_WATCHDOG_TIMEOUT. Searched it up and it said, I need to increas Vcore. What does that mean?
Go back and look at what settings you changed, you should be able to figure it out.
As you've experienced, Cinebench R15 isn't a good stress test. Use OCCT's Large Data Set with AVX enabled
Okay, tyt
Any stuttering before the GPU reaches 70+?
~~Any weird artifacts?~~ Usually artifacts indicate that there is something wrong with the hardware side, but it can be caused by temps. If you suspect thermal pads and paste to be worn out, i recommend replacing them, tho there is a chance that it might be a bit too late if there is any damage to the hardware
Do you mine on it?
Is there any weird fan noises beside the usual wooshing loud sound from fans spinning?
https://www.ocbase.com/ try this if you want
I used: OCCT 8.x.x from https://www.ocbase.com/ - CPU test - Data set: Large - Mode: Extreme - Load type: Variable - Instructions set: Auto - Threads: Advanced Then click on the Advanced Thread Settings button and in that page: - Unselect all Physical Cores but Core #0 - Virtual Cores: Physical Only, - Core Cycle: Cycle Active Core every 5s, - Swap Active/Inactive Cores: Disabled
Just start it after setting all cores to -15 in CO and let it go for 10 minutes. It will show a log line for each time that a specific core gave an error. After 10 minutes of that test you can collect all cores that gave errors in the logs (in my case they were cores 1 3 and 9 for example) , go in your BIOS Curve Optimizer and put cores 1 3 an 9 to -10 and all other cores to -20, then run the OCCT test again for 10 more minutes, and go on with additional negative or positive offset to each core (5 at a time, or 2 at a time later when you want to fine tune). That's all
If no BSOD message, then possibly PSU issue.
Older group regulated PSUs like that seasonic are terrible at voltage regulation and may damage modern components over time: https://superuser.com/questions/1051024/under-what-conditions-will-a-group-regulated-psu-damage-a-modern-computer
I'd run OCCT power supply stress test and see if it passes: https://www.ocbase.com/
Sorry, I just saw that you mentioned it in the post. Yup that sounds like PSU issues.
But there is a small chance the problem is on the GPU side, something going wrong that's making it request more power than expected. Since it's easy to do, make sure to update your graphic drivers if you haven't.
Also try this, the free version will let you run some custom tests: https://www.ocbase.com/
How easy it is to replace the PSU depends entirely on the machine. It's wired to literally every component inside, and some prebuilt ones can have some tight fits.
I've been using the power supply stress test in OCCT. It basically maxes out everything on CPU+GPU.
I find the individual tests (3dmark, cinebench, gaming, etc) never really bring my temps up enough to actually saturate my loop betwen their short runs and limited scope, but OCCT fills my case with HEAT.
My 5800x is the main source of heat in my loop it seems. I had to use PBO2 to undervolt my CPU to keep it in-line with the rest of the system.
Okay, verify your CPU temperature under load, make sure it's not going above 90 C. Use for instance OCCT for this.
Unfortunately there isn't much else you can do other than replacing the CPU and seeing if that solves it.
>16GB 3600 RAM
Are you actually running those ram sticks at 3600 speeds?
Ryzen 2000 series could not reliably run RAM at those speeds. I highly doubt DDR4-3600 is stable on 2700X
To be 100% sure, I would run OCCT memory stress test or TestMem5 extreme config: https://www.ocbase.com/
To avoid viruses make a clean install of windows
To check the condition of the hardare, download OCCT it's free and has many benchmark to detect errors on memory, CPU, GPU, etc.
Negative offset on curve is not literally undervolting, it's a V/F curve. One can't ignore the F which stands for frequency. Check out OCCT benchmark, set to 5600x, AVX load, and you can ignore static OC. At 65A TDC and 90A EDC it'll pull 85-90W.
>how do I further solidify if my OC / Undervolt is stable at all?
Run at least an hour of OCCT: https://www.ocbase.com/
If you want to be stable for NASA, run prime95 small FFTs 2~8 hours
If you do rendering workloads or video editing, maybe make sure it can handle Blender and pass its benchmark: https://opendata.blender.org/
Have you tried using OCCT to check for VRAM errors?, run the VRAM test and put 85% and run it for an hour. After that test your "3D" clocks with shader complexity at 8
If you start getting tons of errors during these tests then there is something wrong with your GPU.
You can run a stress test (with for example OCCT) to try to trigger the crash, but that's it.
If your system is crashing there's always a chance of data loss. Whether that applies to your work isn't obvious, it depends on how you work from home.
Yes, it's possible your PSU is causing this. OCCT has a PSU test you could try. It works by simultaneously creating a high CPU and GPU load.
If you replace the PSU, and it's a modular PSU, only use the modular cables that come with the new PSU. Modular cables aren't standardized and consequently they're not interchangeable between PSU brands and models.
Overclock only one thing at a time and stress test only one thing at a time. Otherwise, you won't know which is unstable if it crashes.
Unless you're stress testing your PSU or you want to know how much power you're consuming with CPU+GPU, you don't need to stress both.
CPU-Z is a horrible stress test.
Use OCCT to stress test: https://www.ocbase.com/
I would say to go install OCCT and run the VRAM test. *Some* games will crash when you run out of VRAM such as GTA V, and in those games you will need to adjust the settings appropriately. Buttt thats a few too many games. I doubt they all have that issue, GTA V and Minecraft are the only 2 I know of.
If you got it new its under warranty still at least, but never fun to be without a gpu for a time.
CoreCycler is the meta, you get it, you run it for hours (like 8-10), and if everything is stable there then it will be stable everywhere.
OCCT is a good contender, but you have to change the default configuration so that it uses only one single core at a time and boost it at max speed for a while.
First make sure everything is within specs, set the RAM no faster than DDR4-2933.
Next try stress testing graphics and CPU separately to see if one of them causes a crash. Try OCCT for this.
Using some program that can read the CPU temperature. For example OCCT, it can read the CPU temperature and create high CPU and GPU workloads.
When you swap the PSU, make sure you only use the modular cables that come with the new PSU. Modular cables aren't interchangeable between PSU brands and models.
Sorry for taking a bit longer to answer! But yes, these resets without error messages or anything are 95% caused by the CPU. By the way, if these temp spikes bugs you, you might want to try to set up a more "aggressive"/responsive fan profile. As in, starting from 60C the fan spins at 70%, 65C 85% and increasing. It does cause a lot of noise and I wouldn't do it myself, since it appears to be very particular cases of when you open certain games.
And on the topic of OCCT, it's a stress/benchmark program that is very easy to use and works really well. Here is the link for it: https://www.ocbase.com/
To really test your undervolt, you want to use CPU, small data set, SSE, variable load. This will really push core clocks and it should be "easy" to detect instability. If you do have some time to spare and want to be 100% safe, before running the OCCT test, go on task manager, set affinity to only one core and it's following threads, example, Core 0 and Core 1 would be your first core and the two threads on it. Then set affinity to core 2, core 3 to test second core and the following threads within it. It is really tedious but it provides a lot of info on which cores to increase/decrease on curve optimizer.
>ram is TridentZ 4200 mhz
Is it actually running at DDR4-4200?
Ryzen 2600X memory controller cannot handle those speeds. The IMC (integrated memory controller) is located on the CPU package nowadays and that mainly determines ram stability and compatibility.
Maybe run OCCT memory stress test and see if that passes: https://www.ocbase.com/
>ast I checked it was x264 loops or Rogbench.
best one is probably OCCT usually finds unstability in less than 3 minutes without crashing the system ( if you didnt do a crazy setting in your bios )
You could go through the Windows Event Log and hope there's some error that shows up consistently before a crash, then search for how to fix it and hope there's a solution.
You could also run a diagnostic suite like this:
https://www.ocbase.com/
You might give OCCT a try. It's a stress test for your system. Even generates pictures, it's a very nice utility.
or
https://www.techspot.com/downloads/4665-overclock-checking-tool.html
Enable ASUS Multi-Core Enhancement in BIOS. That will let your 11700K boost unrestrained to it's stock 4.6 GHz all core limit.
If you wish to try for 5 GHz:
CPU Core Ratio to Sync all cores
All-core ratio limit to 50
 C;
As for making this stable, you have several options, here is the one I would recommend:
V/F Point Offset - Your 11700K should have several points, pick the point that represents 5000 MHz (or 5100 MHz if 5000 is not there), and adjust the offset up if you're crashing, or down if you're having thermal issues
Use OCCT with Large Data Set to test stability
Well, its not about having PC above minimal requirements - you experience not low FPS but crashes - that tells us that something wrong happens between game and probably GPU. I would do two things:
- Check and repair game files from WG launcher
- Do CLEAN reinstall of GPU drivers
If this wont help then I suggest to check other games and do stress testing of components - you can do this with OCCT.
No, avoid Furmark. It's not a stress test, and hasn't been for years. Both AMD and Nvidia detect the software and cut power to the GPU so they don't fry.
For load testing, download OCCT and run the power test. It'll draw the max amount of power your PC can use without damaging components.
I tested first with no CO then re-tested with CO. No CO was around 140A and with CO shifted to 150A. 185A TDC is just wrong. I have seen a CPU run a bit over 190A on static OC, 1.4V+ and on AVX2 it hit 103C. Not healthy. OCCT score WAS better, but barely, and only on all-cores AVX2 bench. There may be some BIOS settings you have on that need to be off, or off and need to be on or smth. Could also be just bad BIOS.
well don't bother wasting your time running 20 3dmark tests, just play your games and enjoy your life.
and when I said "crush", I was specifically referring to how furmark puts an unnatural load on the card.
you can also run kombustor, which is a modified furmark which actually has an artifact scanner: https://geeks3d.com/furmark/kombustor/downloads/
and OCCT, which does something similar: https://www.ocbase.com/
any of these 3 apps are in a different class of test compared to 3dmark and games. there are people who will use their video cards for years and never have a problem, but these tests will fail, showing that the card wasn't actually okay. this is why manufacturers don't like people running them. strong loads don't actually break the cards, they just find broken cards and cost the companies more warranty requests
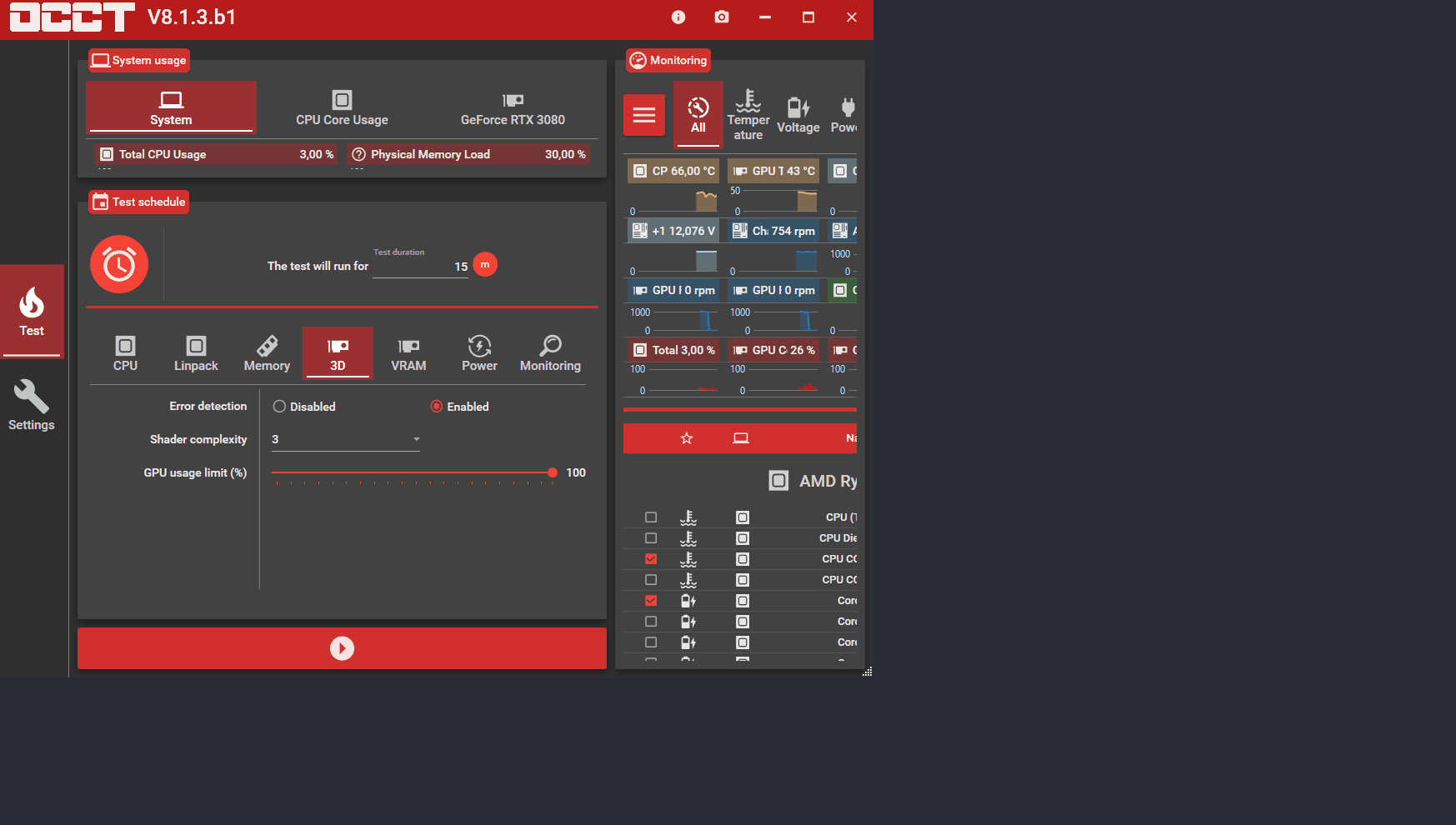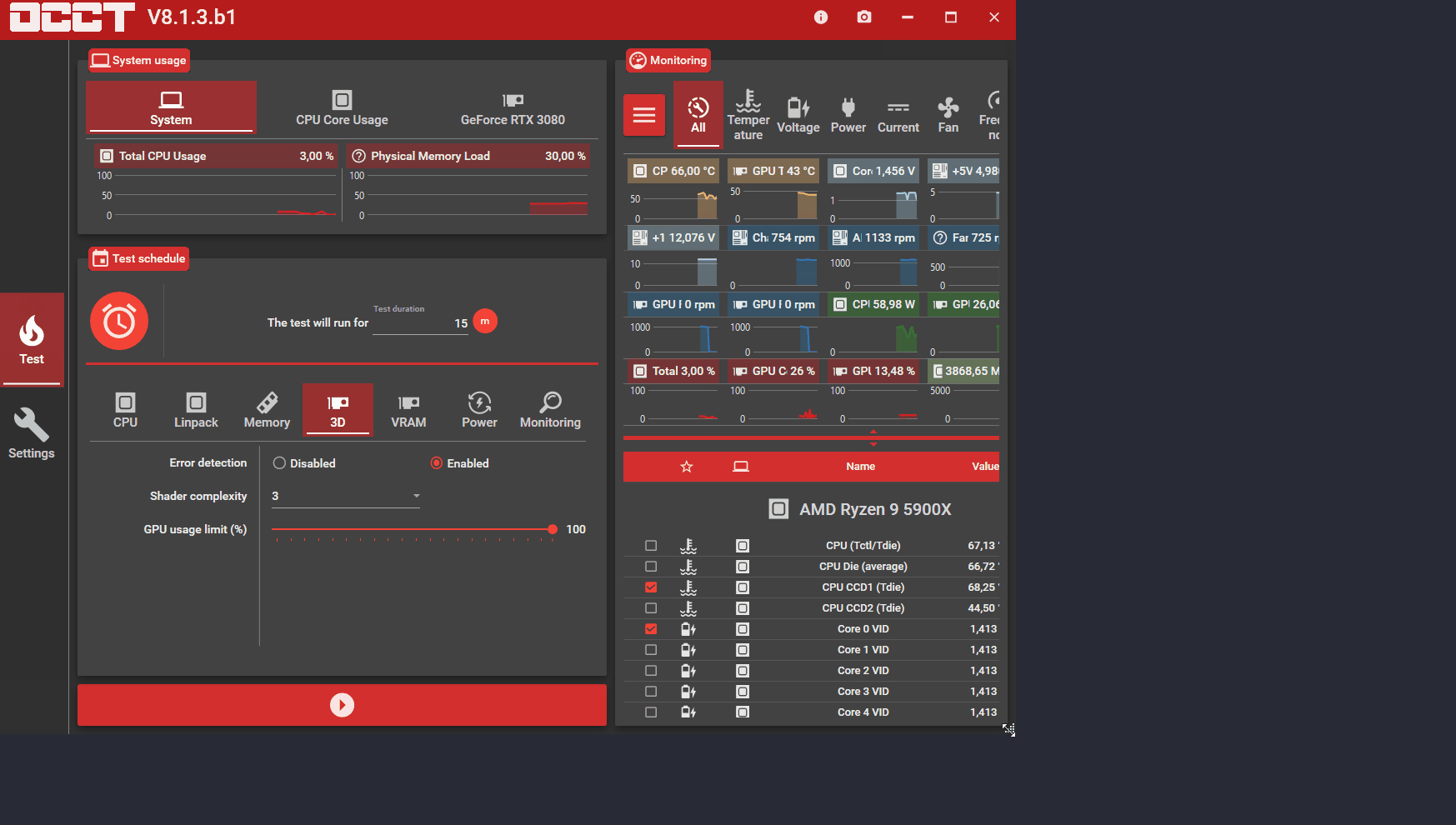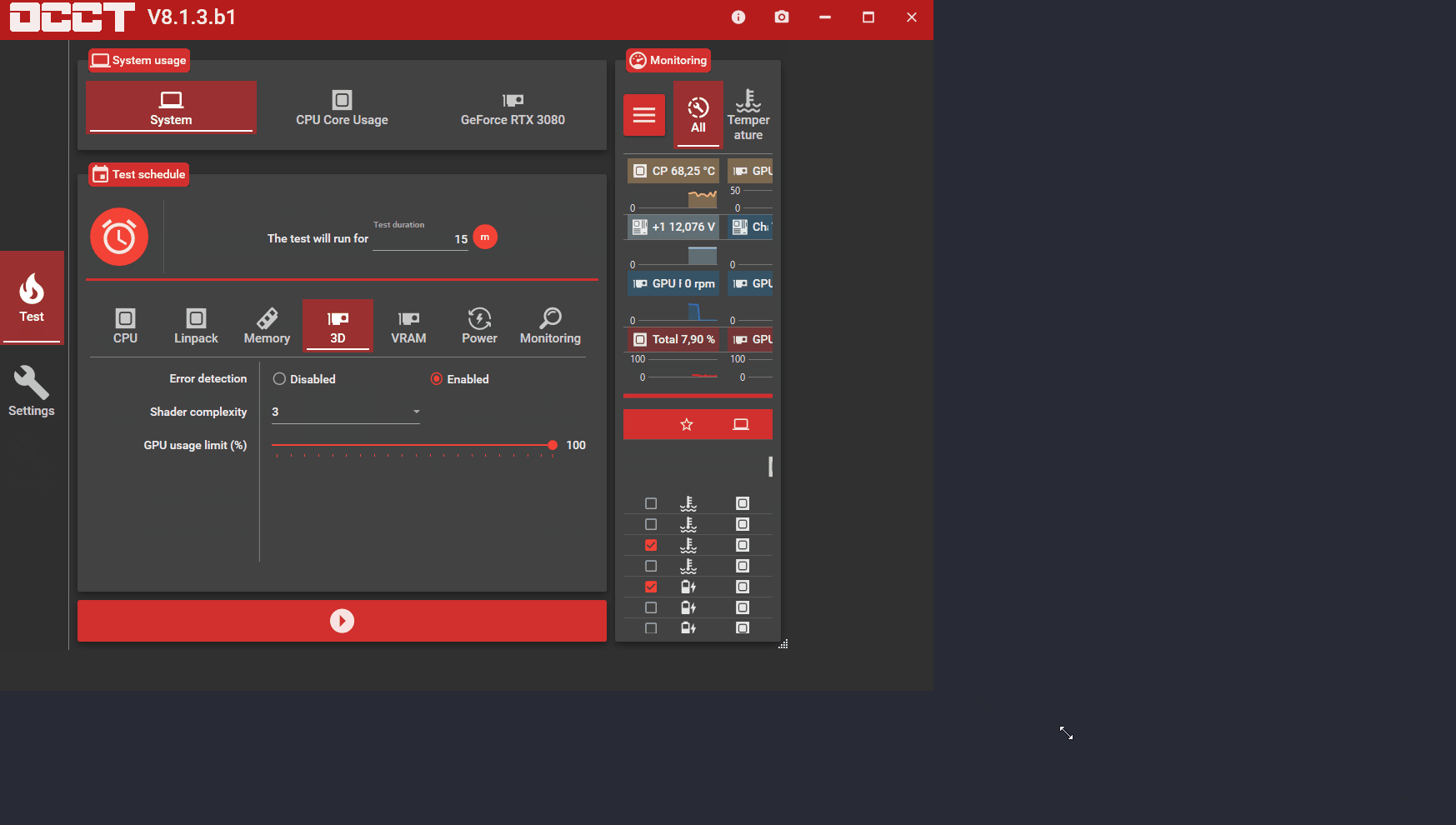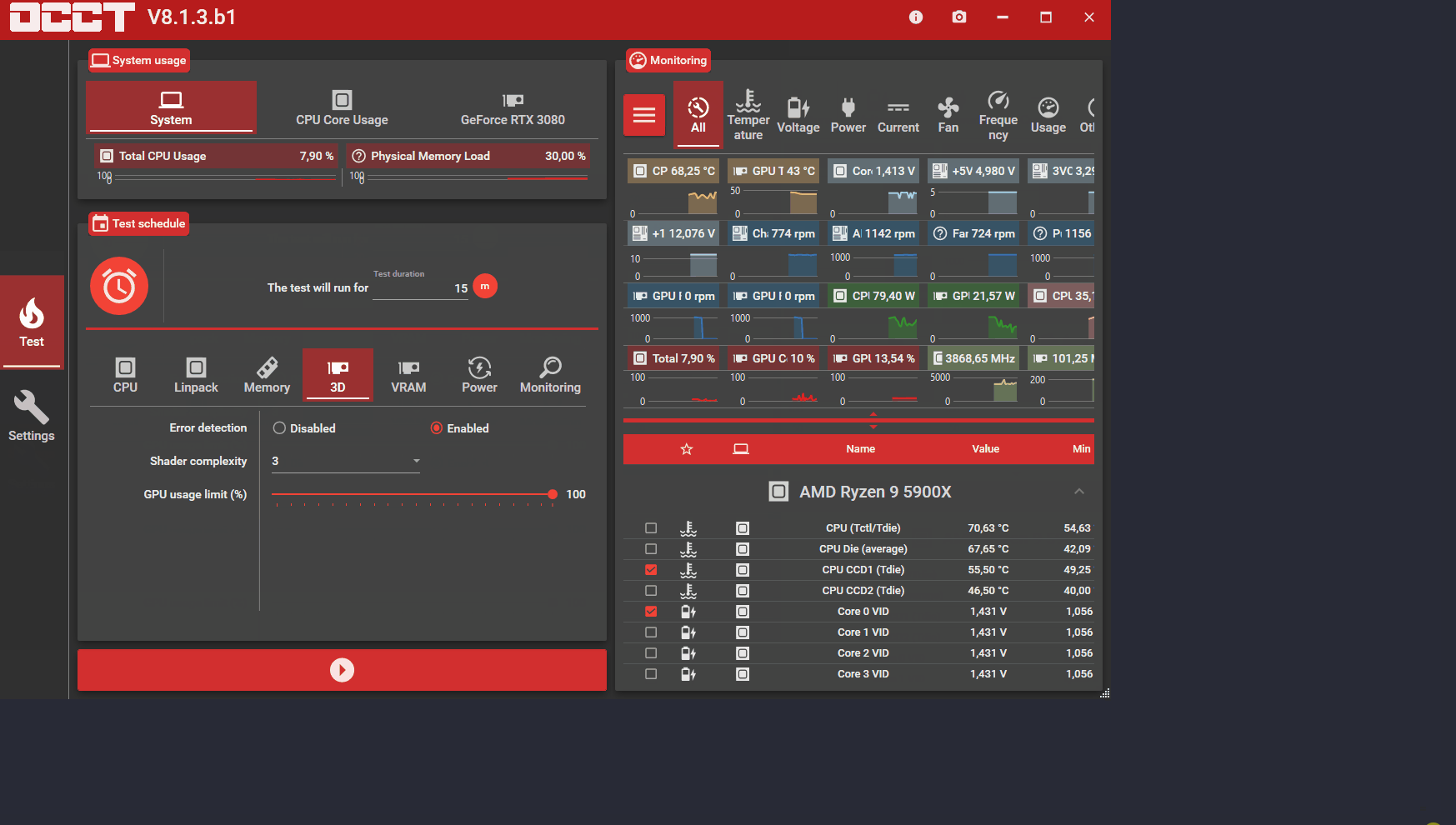
You download OCCT and run the stress test. Default settings are good, actually. I'm running an AMD Ryzen 9 5900x.
Using OCCT I found and corrected most of the problems with my OC fairly quickly. After just running OCCT and fixing issues until OCCT would do full hour-long runs with zero issues, games and 3DMark benchmarks, Cinebench R23, etc. would all run fine. The cores that were just barely unstable were either uncovered during the Blender 6-image benchmark runs or were uncovered by CoreCycler, which stresses each core separately. CoreCycler has the benefit that the single-core runs cause the cpu to boost higher than they otherwise would during all-core stress testing, which can uncover some of these barely unstable conditions.
Run OCCT memory stress test, using default settings: https://www.ocbase.com/
OCCT runs hotter than memtest86. OCCT heats up the memory controller and is more demanding, leading to better error detection.
Run OCCT memory stress test: https://www.ocbase.com/
I doubt that DDR4-3600 is stable on old Ryzen 2000
The memory controller is located on the CPU. 98% of Ryzen 2000's IMC can not handle 3600MHz for DDR4
>windows memory test
Windows memory test is 100% garbage at detecting unstable memory
It could be RAM errors. I've had this error with overclocked RAM and instability on infinity cache (Ryzen) or bad timings.
You could try: https://www.ocbase.com/
Run the OCCT memory stress test for one hour with the standard preselected options. See if you get any errors.
>Seasonic 520W 80 Plus Bronze
If you mean that your PC just shuts off, meaning no power, then it's probably PSU issue
That PSU is decades old in terms of technology anyways. It uses outdated group regulation for voltage regulation. Best to replace it with something more modern.
Group regulated PSU have poor transient voltages: https://superuser.com/questions/1051024/under-what-conditions-will-a-group-regulated-psu-damage-a-modern-computer
Run OCCT power supply stress test and see if that passes: https://www.ocbase.com/
Use DDU to cleanly uninstall graphics drivers, if you haven't tried that: https://www.guru3d.com/files-details/display-driver-uninstaller-download.html
Install latest graphics using clean install.
Run OCCT GPU stress test and see if it passes: https://www.ocbase.com/
So there could be either a bad block in the ram someplace or the cables are not at spec to drive the images. As for the errors you would need investigated and see if they point to ram by googling the codes, this might take some time. Or you can just stress test the card yourself using:
OCCT: a fully features system test that has dedicated parts for the GPU, 1 hour maximum stress test. https://www.ocbase.com/
GpuMemTest: which is only GPU memory and works on virtually all GPU cards. It runs though patterns and blocks and just hits them all looking for errors. http://programming4beginners.com/gpumemtest
Jo, ich nehme an du hast in der Systemsteuerung "Höchstleistung" als Energiesparplan ausgewählt? In dem Fall taktet die CPU einfach nicht runter und läuft immer auf Maximaltakt. Aber die Taktfrequenz ist ungleich Auslastung bzw Leistungsaufnahme und auch bei 4 GHz sollte die CPU nicht 60 °C warm werden.
Mein i5 10400f läuft zB gerade mit 4 GHz auf allen Kernen im Idle, zieht ca. 10 W und ist dabei gerade mal knapp 30 °C warm mit nem Pure Rock Slim @ 800 rpm. Klar ist das ne andere CPU und ein anderer Kühler, nur zur Veranschaulichung der Größenordnung.
Kannst ja mal mit OCCT nachschauen, wieviel Watt Leistung deine CPU im Idle zieht.
Wie andere hier im Faden schon erwähnt haben, ist die Temperatur bei dir halt viel zu hoch, daher die Spekulationen, ob der Kühler falsch montiert ist o.Ä.
Running RDR2 just fine on my Ryzen 2600, zero stuttering with vulkan API: https://youtu.be/JcL34hQTK6k
Vulkan gives me about 10~15 better FPS than dx12
Unstable RAM can cause stuttering.
Are you sure that ram kit is stable at 3600MHz?
Run OCCT memory stress test: https://www.ocbase.com/
Hmm did my other reply disappear? Interesting. Nonetheless, I used OCCT and I would recommend it. It has a built in PSU stress test that will put stress on all of your components to make sure they’re using enough power to test it properly. It will display the voltage you’re getting out of it, and if it’s below what it should be then the machine won’t have enough power and will shut down and it would be safe to assume that you just need to replace it. Good luck and feel free to ask me anything!
I used OCCT so I’d recommend that. It has a built in stress test for your PSU where it will put your components under stress so they end up drawing the most power, and it will display your voltage. So basically if it’s lower than it should be it would likely be your problem, as when the PSU doesn’t have enough juice to power everything, obviously the machine will fail! Good luck and I hope you can figure it out. Feel free to ask anything else
I used OCCT so I’d recommend that. It has a built in stress test for your PSU where it will put your components under stress so they end up drawing the most power, and it will display your voltage. So basically if it’s lower than it should be it would likely be your problem, as when the PSU doesn’t have enough juice to power everything, obviously the machine will fail! Good luck and I hope you can figure it out. Feel free to ask anything else.
You might have any number of faulty parts, but your power supply would be the prime suspect.
https://www.ocbase.com/ Can stress test your system to help diagnose. One thing failing can stay isolated our cause other things to cascade.
This old thread lays out some decent troubleshooting procedures. https://www.reddit.com/r/buildapc/comments/jjkw3i/my_computer_is_shutting_down_randomly_under_load/
Download OCCT: https://www.ocbase.com/ Run the CPU Large Data Set test, and look at CPU temperatures.
If Large Data Set is stable for 1 hour, try the memory stress test. If not, try lowering the memory frequency.
Can you check all the system temperatures? This is free ocbase.com and a bit easier to get around than hwinfo.com if you are new to this.
It could be hitting high temperatures as soon as you start to do something and then stuttering as hits a throttle temperature, or a lot of the time this can be from Power Profiles on really low settings to save battery, and stuttering happens as it's struggling to wake up the thing it needs to use.
While drawing that can happen definitely, what program you use, how much ram you have, how good the GPU being used is can have a huge affect on that as well. Post those details from OCCT here, the temperatures, amount of RAM, GPU, GPU RAM , and what programs you are running.
One way to check the graphics would be to use OCCT, the free version will do just fine: https://www.ocbase.com/
That program may be Windows only. You can stress both the GPU and its memory. I would monitor temperatures closely too, if they shoot up past what's safe for a RX580, I'D stop any kind of testing since it means the GPU is due for a cleaning and/or repaste.
A faulty graphics card should cause issues either when stressing the GPU itself or when stress testing the memory.
OCCT memory stress test imo is faster and better at catching unstable RAM: https://www.ocbase.com/
Those errors you're getting seem to be RAM related.
Especially if DISM is detecting that your system files are corrupt.
Run a memory stress test: https://github.com/integralfx/MemTestHelper/blob/master/DDR4%20OC%20Guide.md#memory-testing-software
Unstable ram can cause worse performance.
OCCT has a decent SSE/AVX based memory stress test as well: https://www.ocbase.com/
XMP is overclocking
https://en.wikichip.org/wiki/intel/xmp
>XMP is intended to make overclocking easier and more accessible to new users through profiles and predefined overclocking configurations that are known to be stable.
1.35V is XMP standard spec. XMP varies between 1.35v~1.5v
Whether it will work or not, is up to luck. Anything over 2933 is a gamble on 12nm ryzen's IMC
Your PSU is way more than enough. Even at 1.5v, DDR4 doesn't pull more than 20W
Always run RAM stress tests, even for XMP profiles
OCCT has a decent memory stress test: https://www.ocbase.com/
In Just Cause 3, you should be getting around 112FPS average at max settings, with a stock Ryzen 2600: https://static.techspot.com/articles-info/1627/bench/JC3-p.webp
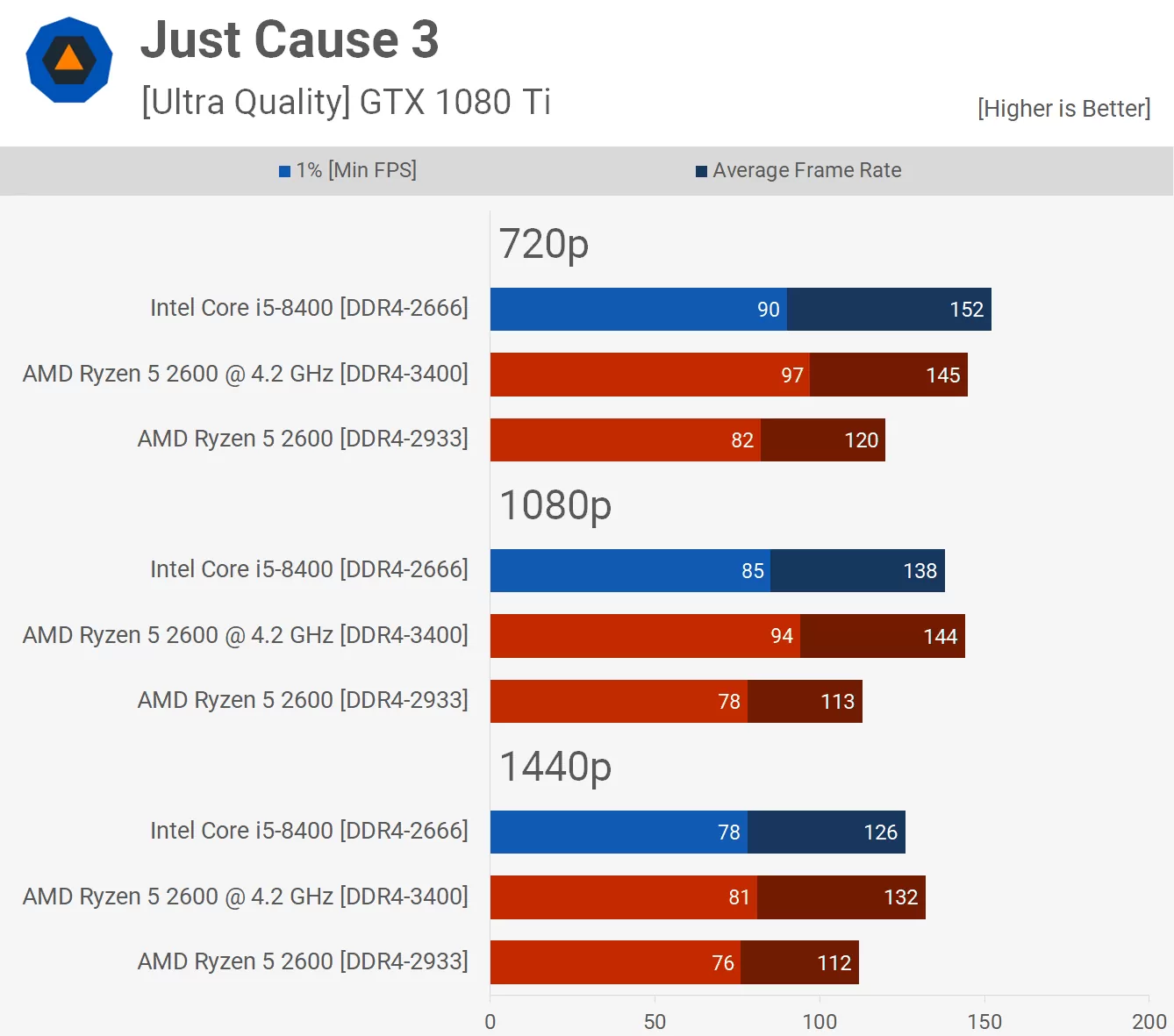{kind=link}
Their minimum FPS was 78FPS. Your PC is vastly underperforming.
Did you enable XMP profile for your RAM? Run OCCT memory stress test to make sure it's stable: https://www.ocbase.com/
Are you measuring temperatures of your hardware? Anything getting too hot?
Run Cinebench R23 as well to make sure your CPU scores are normal.
Run 3dmark time spy to make sure your Vega 56 is scoring properly.
>set the ram speed manually to 3200 mhz
Run OCCT memory stress test
Overclocking ram is not guaranteed to work. Those bsod messages are usually related to unstable memory
Ryzen 2000 series officially only supports ddr4-2933
>without drivers it works with no error, how is that possible?
No drivers, no actual gpu load. Drivers are needed for gpu hardware shaders to function properly.
Seems your card's vram is dying
I would run OCCT vram stress test and see if any errors pop up
Claim warranty if errors pop up
While you've done what you can, maybe someone else can diagnose your problem with just the BSOD errors...if you post them. The TechSupport reddit seems to be the only one where anyone might be willing to download some random zip file, you're unlikely to find anyone here willing to do that...but, whatever...
From a hardware perspective, you've got three main possibilities, mobo/cpu/psu. It could also be some little before seen cause of random and varied errors, but usually random and varied errors, if they're not RAM, are either CPU/mobo or PSU(assuming you've done the basics and removed any OC and updated your bios). A weak/insufficient/soft failing psu can be an extremely difficult to diagnose problem, since it can mostly work. Same with a bad CPU, but often, bad CPU's can be replicated by specific situations. A bad motherboard generally has a consistency to the issues, for instance, freezing is an often seen symptom of a bad motherboard in AMD builds.
Download OCCT(https://www.ocbase.com/) and run the psu test, see if you can force it to fail while running that...it won't definitively rule out your psu, but it could help indicate whether the psu is creating an under-voltage condition, since its a psu stress test.
Then it's probably a hardware issue, either PSU or motherboard
Are there any LED lights being lit up on your motherboard when your PC suddenly reboots?
Can you run OCCT power supply stress test?: https://www.ocbase.com/
I would watch the voltage rails to see if any abnormalities like the 12v rails dropping too much below 12v
Replace your psu.
If you want to stress test your psu, use this: https://www.ocbase.com/
PSU's often don't fail catastrophically nowadays, since they have so many protections built in. More common is soft failures where they only kind of work, but fail for over voltage, under voltage, or heat...
That definitely doesn't seem like heat is the issue then, maybe a power supply going out? Unfortunately that's the type of thing that you need a technician for, a power supply tester can reveal if the voltages being provided are too low. It could also be something like a bad stick of RAM. At this point it becomes an issue of troubleshooting each individual component.
OCCT has some stress tests for CPU, GPU, RAM, etc. that might be able to help you narrow it down
But it isn't a surefire answer to anything.
Yes, the Noctua is awesome. 'Keep it!
OCCT, is a great indy program. has every kind of synthetic test under the sun, and even some you have never heard of.
https://pasteboard.co/K4E3IkF.png
{kind=link}
Power "virus" is just a tongue in cheek term I picked up from Gamer Nexus to describe burn in software. they are not viruses in any way shape or form.
furmark, Ryzen Master, CPU-Z, these are all the same kind of thing.
OCCT has several options. More than all the others. ONE is power. It cranks up you CPU and GPU to the the max.
Its all for stability testing etc.
As for Zalman, the ONLY reason I brought it up is because its new double tower air cooler is the only one that beats the Noctua that you have,.
BUT, your Noctua cooler is enough for these Ryzen 5000 chips. these c hips just run hot.
anyways, you can always run the chip in eco mode, set the max temp in bios manually, undervolt, or use Ryzen tuner ( CTR 2.1 ) to automatically find settings to run these chips at, that are different from stock in some way.
Sounds like untable RAM. XMP/DOCP ram profiles are not guaranteed to be stable, especially on older ryzens.
The IMC(integrated memory controller) on the CPU package mainly determines RAM compatibility
Can you run OCCT memory stress test: https://www.ocbase.com/
I used OCCT: https://www.ocbase.com
If you happen to have a spare PSU or know someone that does ask them if you could borrow it and swap out yours for that one. Essentially if your computer turns off whilst under load like from the program above it means that it is not program specific. As your system is launching the program and drawing more power your PSU can’t provide what your components need so then your computer shuts off and reboots.
Failing that and if you are not comfortable poking around the inside of your computer, take it to a pc repair shop and ask them to test the PSU for you.
I bought a Seasonic to replace my Corsair PSU. Not a good idea to go cheap, as if it messes up it can fry everything or catch fire which is obviously worst case scenario
If your CPU is overheating that could cause this, but a machine Check Exception means the CPU has detected an internal or external hardware level error.
First make sure your CPU isn't overheating. You can test it with OCCT. Also try testing your video card with OCCT.
Looking at the crash scenario (stack pointer in Intel Processor Power Managent) and other error data, most likely something is wrong with your CPU. Possibly a BIOS update might solve this if OCCT doesn't crash your machine.
I would maybe stress test your XMP profile with OCCT memory stress test section: https://www.ocbase.com/
Run it at the default settings 1 hour.
Unstable RAM may be causing worse CPU performance. The CPU may be spending cycles correcting errors, which in turn reduces CPU performance. XMP may be on the edge of stability where you don't get crashes, but instead get worse performance.
Other than that, I'm not sure what else could be causing your low 6400 score in Cinebench R23
Those are acceptable temps for idle.
You could download OCCT and run some tests to see what breaks the back of the donkey. Although your ram is relatively slow compared to what’s available today, might be worth starting with the memory test, and running it for an hour.
You can also downloadBlueScreenView to check some of the details of your previous bsods.
Randomly shutting off isn't caused by a problem with the SPDs.
The SPDs are only read before the POST when the system configures the memory. Or if you explicitly read them with Thaiphoon Burner or CPU-Z, etc.
The most common causes for randomly turning off is a bad/inappropriate PSU or a very badly overheating CPU. Try running OCCT's various stress tests and see if you can isolate the problem.
I wouldn't worry too much about these CRC errors. If your system still boots correctly it's either some small bug in the module SPD data or in Thaiphoon Burner.
This is pretty basic, but How are your CPU temps?
CPU overheating will crash and trigger CPU debug light
Are you running any RAM XMP profiles? Disable them.
I would run OCCT stress test to see if your CPU passes it at stock : https://www.ocbase.com/
> do I just change the voltage to 1.375?
You can. Depends on your CPU cooler. Can your CPU cooler handle that? 1.375V is pretty hot.
>is there anything else I need to set
You need to set a clockspeed ratio of course in the bios. But that's mostly it. Just set voltage and clockspeed ratio.
>should I just run heaven benchmark or cinebench for an hour?
Heaven is a GPU benchmark.
Cinebench is just a CPU benchmark, not a stress test.
Run OCCT Large data set for one hour at least: https://www.ocbase.com/
If you do workstation tasks, it's recommended to run longer, or use y-cruncher or prime95 as a stress test if need solid stability.
Looks like unstable RAM related BSOD
Did you enabled XMP profile?
Disable XMP profile and then repair system files using elevated CMD prompt.
sfc /scannow
dism /online /cleanup-image /restorehealth
I would reinstall graphics drivers as well afterwards. Seems your RAM may have corrupted GPU related driver files
In my experience, when WhoCrashed told me "not related to hardware", it eventually was.
If no XMP, run OCCT memory stress test to make sure RAM not defective: https://www.ocbase.com/
What kind of crashes? BSOD? DXGI errors?
I would maybe run WhoCrashed 6.70 to find out more details: https://www.resplendence.com/downloads
If you are getting CTDs or BSODs, I would run OCCT RAM/Memory Stress test: https://www.ocbase.com/
Use the default settings and 1 hour stress test
(replying to myself)
After spending two hours on this, my conclusion is that there's very little I can do. Most of it seems related to WPF technology. As soon as I start adding controls, the resize gets laggy, the larger the window, the longer the resize is.
The best "result" I could get is to delay updating the window content's resize until you let go of the drag. It's not final, but here's a preview. Makes things feel "faster" at the cost of the preview : https://www.ocbase.com/misc/resize.delay2.gif
{kind=link}
What are your initial thoughts seeing this ? :)
That's good to hear. Still, I'd recommend making them sweat a bit with OCCT (or whatever else you might trust) just to make sure there are no lingering memory errors waiting to happen. If you can leave it running for the 1h the free version allows would be good.
Try running OCCT's PSU stress test, it's the closest to a very high gaming workload.
This could be a problem with your PSU or the video card. Personally I'd look at the PSU, despite what some people claim, in my experience the EVGA BR 500 isn't a good PSU. I've helped several people with defective ones over the years, more than most other PSU types (worse PSUs do exist, like Diablotek, EVGA n-series, etc).
Not really, if it’s artifacting and mats can’t detect it the first time, i would recommend you to run OCCT gpu memory test for a while until it starts to produce errors and then run mats again to confirm the error.
Edit. Link - https://www.ocbase.com
Give OCCT a try and do some stress testing on individual components: https://www.ocbase.com/
My guess would be a RAM or VRAM fault, but can't really make a high confidence guess without more info.
Get rid of the new drivers. Roll back to 21.2.3.
Also get rid of any RGB software linked to the car (just an experiment, getting rid of mine helped) and do CCleaner do delete the reg files left over. Then run a https://www.ocbase.com/ test.
Then I would think it is a power supply issue like others are saying. Download OCCT 8.0.1, its a stress testing tool - https://www.ocbase.com/ and run the Power stress test. This should throw you some errors if the power supply is the issue.
Very likely your PSU is either not powerful enough or it's malfunctioning, especially if you have to fully power cycle the PSU after this happens (unplug or toggle the switch on the back). Only a few other things can cause this, for instance a very badly overheating CPU.
You can use OCCT's various stress tests.
Looks like vram artifacts from when I overclocked the GPU memory too much
Can you run OCCT VRAM stress test? https://www.ocbase.com/
If any errors pop up, and your GPU is 100% at stock configuration, then your GPU is probably defective
>Oley 16gb 3000 ram
Are you running XMP/DOCP profile for your RAM?
Might not be stable. XMP is not guaranteed to be stable and can cause silent corruption.
Run OCCT memory stress test to make sure: https://www.ocbase.com/
I recommend running OCCT, specifically the AVX RAM test; the free version of OCCT allows to run tests for up to 1 hour, which is the minimum time I recommend.
From MemTestHelper/DDR4 OC Guide.md
>OCCT with the dedicated memory test using either SSE or AVX-instructions.
>
>Note that AVX and SSE can vary in error detection speed. On Intel-based systems, SSE appears better for testing IMC voltages while AVX appears better for DRAM voltage.
>
>The Large AVX2 CPU test is a great stability test for your CPU and RAM at the same time. The more you tune your ram the harder it'll be to stable in this test.
Remember - always stress-test any RAM setting outside of JEDEC spec, which XMP is.
If you get an error - the XMP is unstable. This can be fixed with some work. If there is no error, either the test is ineffective at detecting it or the problem is elsewhere. So please tell me the result, I will help you.